



What Is AI Code Refactoring?
At its core, the approach uses artificial intelligence to identify and fix structural problems in an application.
Throughout the process, the software’s behavior stays unchanged. Every product runs on an accumulated body of software. Over time, it accumulates problems that make the software harder to update and extend:
- Redundant logic — the same operation written in multiple places, so a single change has to be applied everywhere it appears
- Outdated patterns — logic written against older standards that no longer fits how the rest of the system works
- Unused sections — portions of the system that are no longer called or needed but remain, adding complexity without contributing function
Line by line, a developer must review the software to catch these issues manually. Across a large project, such a process produces inconsistent results and takes significant engineering time.
How thoroughly problems are detected depends on each developer’s familiarity with the software. In a small, well-documented project, the task is workable. Scale changes the equation. Detection becomes incomplete, and the work competes with active development for engineering time. These tools change the conditions by automating detection and generating suggestions.
Two layers drive this process:
- Static analysis scans the architectural structure to find the patterns automatically
- Large language models, or LLMs, approach it the way an experienced developer would
Together, they surface problems that affect code quality and suggest changes that reduce routine maintenance work. For businesses, the practical outcome is improved developer productivity. It means that engineering teams spend less time on updates and more on features that move the product forward.
How AI Code Refactoring Works
Understanding the value artificial intelligence delivers starts with understanding what it actually does at the source level.
Code refactoring AI operates across three connected layers. Structural problems are identified, prioritized, addressed, and validated inside the existing workflow. Each layer depends on the one before it.
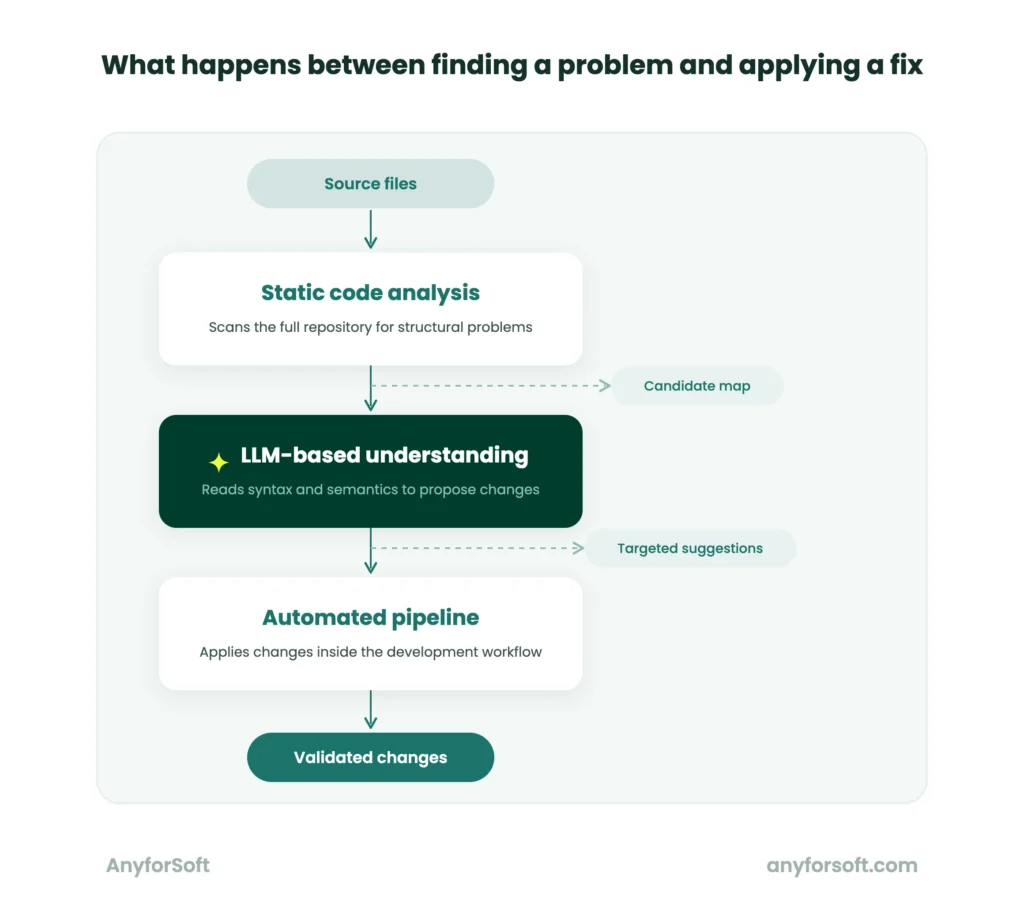
Static Code Analysis and Pattern Recognition
The scan runs before any suggestion is made. It covers the entire project, not just the sections currently under development. Code smell detection operates at this stage, identifying patterns that signal poor design or future maintenance risk.
Anti-patterns are what the analysis targets. These are recurring structural problems that, while not breaking the software, degrade its long-term reliability. Duplicated logic and overly complex modules are common examples. Each one makes future changes harder to apply correctly.
The output is a prioritized map, ranked by structural risk, produced before a single change is proposed. Engineers use that map to decide where to focus first.
Pattern recognition is what makes this consistent at scale. A manual reviewer applies different standards across different sessions. The system applies the same criteria to every file, every time, without variation.
LLM-Based Code Understanding and Suggestion
Detection identifies where problems are. Understanding them requires something more than pattern matching. Large language models, or LLMs, bring a second layer of analysis. They read software the way a developer would, parsing both its syntax and its meaning.
Syntax refers to the structure of the application: how it is written. Semantics refers to what it does: how its parts relate and what they produce together. An LLM works across both levels simultaneously. This allows it to propose targeted, context-aware changes. Generic fixes applied regardless of surrounding logic are replaced by specific transformations.
The suggestions that come out of this process are specific. The model does not simply flag a block as problematic. It proposes a concrete transformation: what to change, where, and why the change improves the structure. Each suggestion carries the context that produced it.
One LLM may handle the same function differently across three modules, based on how each instance is used. That sensitivity to context separates LLM-based suggestions from rule-based automation. Rule-based automation applies the same fix to every matching pattern, without considering the surrounding logic.
Automated Refactoring Pipelines and CI/CD Integration
Inside the team’s existing workflow is where AI automated code refactoring becomes most effective. Treating it as a separate manual step reduces that effectiveness significantly. Suggestions from the analysis and LLM layers feed directly into automated pipelines. Those pipelines apply, track, and validate changes without interrupting how engineers work.
Before it reaches production, the build passes through a sequence of automated gates.
Production is the live version of the software that end users interact with. That sequence is called a pipeline. Each proposed change enters the pipeline at a defined point, where it is applied, tested, and checked against the existing build.
For building these pipelines, GitHub actions is a widely used platform. Pipeline stages can be configured to run automatically when work is submitted for review.
Within the pipeline, the following operations are typically configured:
- The pipeline activates automatically when a developer submits work for review, requiring no manual intervention
- The full repository is scanned for structural problems before any changes are proposed
- Approved changes are applied automatically to the submitted changes within the same pipeline run
- The updated version is tested immediately to confirm it produces the same outputs as the original
- Any suggestion the system cannot validate automatically is routed to an engineer before the change proceeds
The overhead of running this as a separate workstream is what this integration removes. Changes are proposed, applied, and validated within the same process the developers already use to ship releases.
Human-in-the-Loop Review and Validation
Automation handles detection and suggestion. Code review by a human engineer determines whether a suggestion is actually applied. Every generated change passes through a review step before it is merged into the main application.
The reason this review is non-negotiable is context.
An LLM reads the source it is given. It does not know the business decision behind a particular implementation. It cannot account for a workaround a team introduced for a specific client. The constraint that made an unusual structure the correct choice lives outside the source itself.
A suggestion that improves structure on paper can break intended behavior in practice. The review is where that gap is caught. Engineers examine each proposed change against their knowledge of how the system is actually used.
Validation follows review. Before any change is merged, it is tested against the original. The updated version must produce the same outputs as what it replaced. This separates structural improvement from behavioral change: the core principle of safe practice.
The human-in-the-loop model does not slow the process down. It makes the output reliable. Automation handles the volume; engineers handle the judgment.
What AI Can Refactor — and What It Can’t
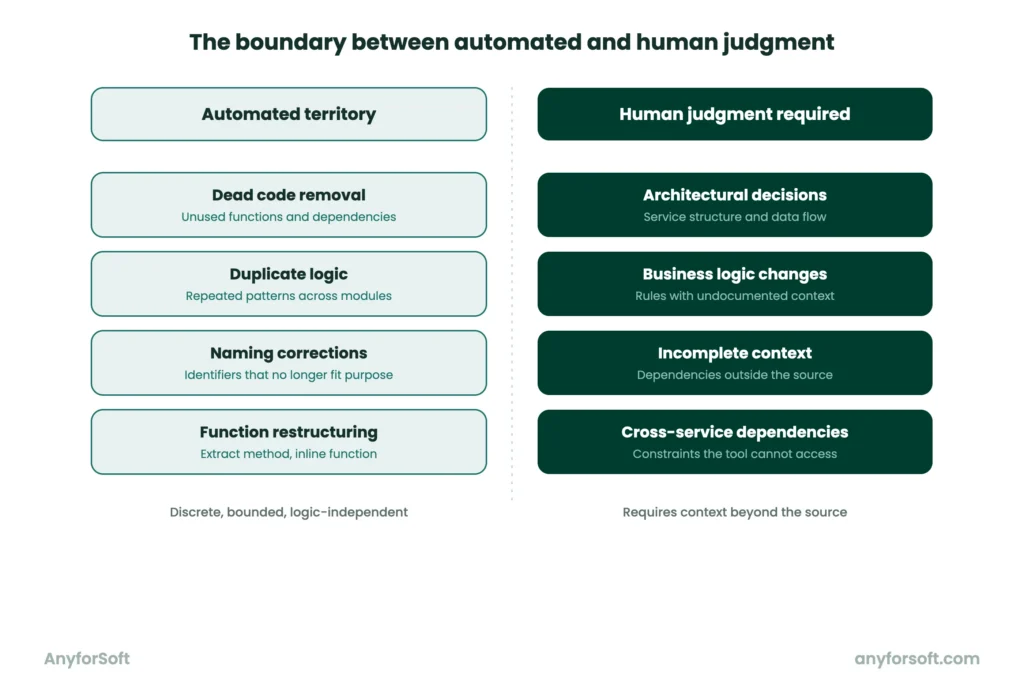
The layers described above operate within a defined scope. Discrete, logic-independent problems are reliable territory. Everything else requires human judgment.
Operations such as extract method, rename variable, and inline function are reliable territory. The extract method pulls a repeated block of logic out of a function. It turns that block into a standalone, reusable unit. Rename variable replaces unclear naming with something that reflects actual purpose. Inline function collapses an unnecessary intermediate layer back into the calling function. Each of these changes is bounded, testable, and verifiable.
Beyond individual operations, the tools handle duplication across modules and unused functions. Poorly structured tests and legacy sections with no active dependencies are also reliable candidates. A function called from nowhere, a test covering a deleted feature: the analysis surfaces these consistently.
Architectural decisions sit outside this scope. How the solution is structured at a system level carries business context the tools cannot access. Which services communicate with which, where data flows: those decisions belong to engineers.
Business logic presents the same boundary. A rule embedded in the app’s behavior may look like an inefficiency structurally. Changing it without understanding why it exists produces a cleaner structure and a broken product.
Incomplete context is the third boundary. An LLM works with what it is given. A function depending on a configuration file the tool has not seen produces suggestions based on partial information.
The same applies when a module interacts with an external service outside the analysis scope. The output may be structurally sound and operationally wrong.
Best AI Tools for Code Refactoring
The range of AI code refactoring tools available in 2026 covers everything from editor-level suggestions to pipeline-level analysis. Each tool occupies a specific position in the workflow. Some focus on individual developer productivity inside the editor. Others operate at the pipeline level, scanning the full repository on every submission. Knowing which tool fits which context determines how much value each deployment generates.
GitHub Copilot and Copilot Chat
At the point where developers write, AI-powered code refactoring is what GitHub Copilot and Copilot Chat deliver. Working inline inside the editor, Copilot suggests completions and improvements as each function takes shape. The surrounding context is what it reads to propose changes that fit what is already there.
Natural language is what Copilot Chat adds to that capability. A developer describes what needs to change, and the model proposes the transformation. Across VS Code, JetBrains, Visual Studio, and Eclipse, the two tools work together seamlessly.
Applied during active development, the tools handle function-level improvements and naming corrections most reliably.
For organizations already using GitHub as their primary platform, the integration requires minimal setup and fits naturally into the existing review process.
Cursor IDE
Rather than an extension added to an existing environment, Cursor is built as a purpose-built editor. Multi-file awareness is its core capability. Across the full project, it reads how modules relate and proposes changes that account for those relationships.
In plain language, a developer can describe a structural problem and receive a targeted transformation spanning several files. That combination of natural language input and cross-file output separates it from tools that operate at the single-function level.
In environments where changes in one module consistently affect others, this makes it a strong fit. It is most commonly adopted as a primary development environment rather than a supplementary tool, which reflects how deeply it integrates into the daily workflow.
Amazon Q Developer
Applications built and maintained on AWS infrastructure are where Amazon Q Developer is purpose-built to operate. Continuously, it scans for vulnerabilities and flags patterns that conflict with AWS best practices. Before they reach production, issues are surfaced and prioritized.
Legacy transformation is its most distinctive capability. Older Java applications can be rewritten against modern standards automatically, reducing the manual effort that such migrations typically require. For engineering groups facing large-scale modernization, this alone justifies the investment.
Running large AWS workloads is where it performs best, keeping infrastructure-adjacent logic current without dedicating engineering cycles to it manually. Outside the AWS ecosystem, its advantage narrows significantly, and other tools in this list serve general-purpose needs more effectively.
Sourcery
Narrow by design, Sourcery focuses on Python and operates closer to the static analysis end of the spectrum. Four categories of structural problems are what it targets: redundant logic, overly complex functions, inconsistent naming, and patterns that violate established Python standards. That narrowness keeps suggestions precise.
With an explanation attached to each suggestion, the engineer understands what is being changed and why before accepting it. Building trust in the tool becomes easier as a result.
Through integration with GitHub and GitLab, improvements surface during the review process rather than requiring a separate session. Those maintaining large Python projects use it to keep standards consistent across contributors, particularly when the contributor base is distributed or growing quickly.
DeepSource and SonarQube AI
At the repository level rather than the individual file level, both platforms approach structural analysis. Continuously, DeepSource scans every submission for issues across multiple languages. A prioritized list of improvements is what it produces, feeding directly into the development workflow.
To its established static analysis engine, SonarQube AI adds a layer of intelligence. Patterns that rule-based checks alone would miss are what it surfaces, extending the platform’s reach into territory that previously required manual review.
In focus is where they differ. Around developer workflow integration, DeepSource is built, keeping the feedback loop tight. Around quality governance and reporting, SonarQube AI is built, giving leadership visibility across the full engineering organization.
Larger operations needing that organizational-level view tend to favor SonarQube AI. Smaller operations moving fast tend to favor DeepSource.
Tabnine and Windsurf (Codeium)
As completion and suggestion tools inside the editor, both Tabnine and Windsurf operate, yet serve different organizational priorities. Across the major editors, each integrates and supports a wide range of languages. The choice between them is rarely about capability and almost always about context.
With data privacy as a core design principle, Tabnine is built. Entirely on the organization’s own infrastructure, it can run, keeping all activity within the organization’s security boundary. In regulated industries where data residency is a requirement, this makes the tool the default choice.
A broader feature set at the IDE level is what Windsurf, formerly known as Codeium, offers. Multi-file context and natural language instructions are included. It makes it closer in capability to Cursor for engineers that do not need on-premise deployment. Between compliance requirements and feature depth, the decision typically falls.
How to Use AI for Code Refactoring: Step-by-Step
Selecting a tool is not the same as deploying one effectively. The process below is cumulative: each element builds on what the previous one produces. Skipping a stage does not accelerate the work. It removes the foundation the next stage depends on.
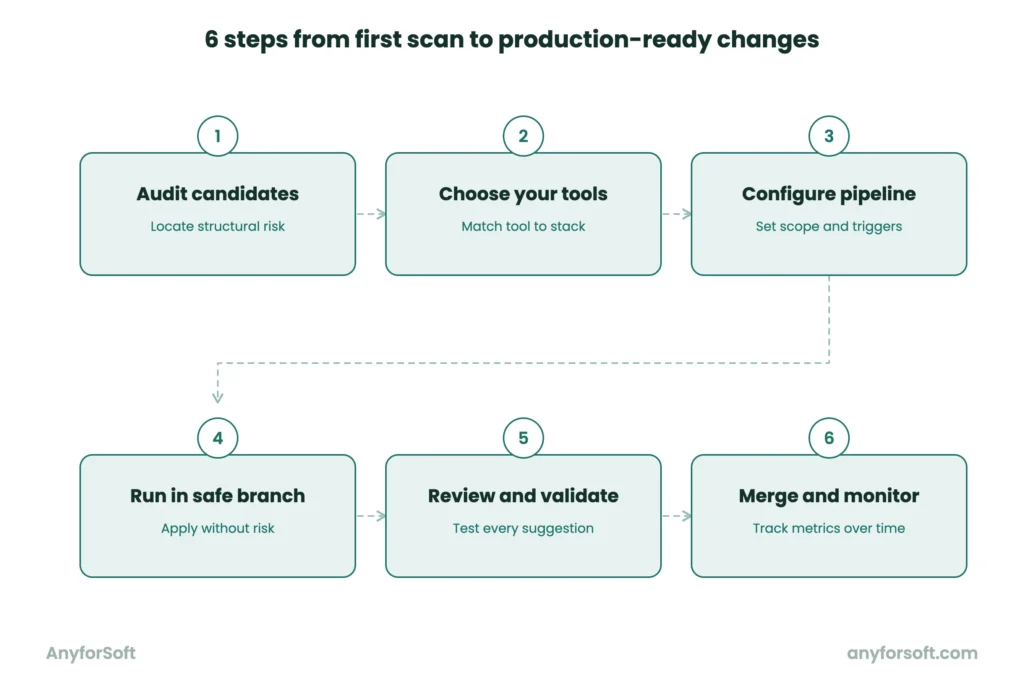
Step 1. Audit and Identify Refactoring Candidates
A structured software audit is where the process begins. Without it, changes are applied based on assumption rather than evidence. What the audit produces is a map: where structural risk is highest and where improvement will have the most impact.
The audit covers the full repository. Function complexity, duplication rates, and unused dependencies are measured and recorded. Static analysis handles the mechanical part of this. An engineer reviews the output and applies judgment about priority.
A well-executed audit surfaces candidates that are discrete, bounded, and safe to address without touching business logic. Those are the starting points.
Step 2. Choose the Right AI Tool for Your Stack
The audit output informs tool selection. A Python-heavy project points toward different options than a Java-based enterprise system. Language coverage, IDE compatibility, and pipeline integration are the practical filters.
For editor-level work, VS code extensions offer the most direct path. GitHub Copilot, Sourcery, and Tabnine all operate at this level, surfacing suggestions inside the environment where development already happens. For repository-level analysis, pipeline-integrated platforms serve the need better.
The right fit is the one that operates closest to where the work actually happens. A tool that requires a separate workflow will be used inconsistently. One that integrates into the existing environment will be used by default.
Step 3. Configure AI in Your IDE or CI/CD Pipeline
Configuration determines how reliably the tool performs. An unconfigured tool produces generic suggestions. A configured one produces suggestions calibrated to the project’s specific structure and standards.
At the IDE level, configuration means connecting the tool to the repository and setting the scope of analysis. At the pipeline level, it means defining when analysis runs and what it checks.
Linting, which scans the source automatically for style violations and formatting inconsistencies, is typically configured alongside static analysis at this stage.
Linting and static analysis both run on every submission, keeping feedback continuous.
Access controls are set here as well. Not every suggestion should reach every contributor automatically. Defining which changes require human approval before they are applied is part of configuration, not an afterthought.
Step 4. Run AI-Suggested Refactoring in a Safe Branch
A branch is an isolated copy of the project where changes can be applied and tested without affecting the main version. All suggested changes run here first. Nothing reaches the main application until it has been validated in this environment.
The safe branch contains the full context of the change. What was suggested, what was applied, and what the analysis flagged as a risk are all recorded. This creates a reviewable history before anything is merged.
Running changes in isolation also makes rollback straightforward. If a suggestion produces an unexpected result, the branch is discarded. The main application is unaffected. That containment is what makes it safe to apply suggestions at volume.
Step 5. Review, Test, and Validate All Changes
Every suggested change in the branch passes through review before it moves further. An engineer examines each one against their knowledge of how the affected module is actually used. Structural improvement on paper is not sufficient justification on its own.
Automated testing runs immediately after review. Each modified function is tested against the original to confirm the output match. For a broader view of how this stage connects to modern verification practices, AI in software testing covers the subject in depth.
Security validation runs in a separate pass. Snyk scans the modified application for vulnerabilities introduced or exposed by the changes. This is particularly relevant when the refactored sections interact with authentication, data handling, or external services.
What this step produces is a validated set of changes: structurally improved, behaviorally unchanged, and cleared for security. Only that set proceeds.
Step 6. Merge, Monitor, and Iterate
Merging is not the end of the process. It is the point at which the changes enter the live environment and their real-world impact becomes measurable. Complexity scores, test coverage rates, and error frequencies are recorded before and after.
Monitoring reveals what the metrics do not capture immediately. A change that passes all tests may still affect performance under real usage conditions. The first weeks after a merge are where those effects surface.
Iteration closes the loop. What the monitoring reveals feeds back into the next audit. The candidates identified in stage 1 are refined against what has been learned. Each cycle produces a cleaner starting point than the one before it.
AI Code Refactoring for Legacy Systems
Modernisation does not always begin from a stable foundation.
Where structural problems have accumulated over years, code refactoring AI delivers its highest commercial value.
Manual resolution is no longer viable at that scale. A legacy codebase presents a specific set of conditions: undocumented logic, missing tests, and dependencies that exist nowhere in writing. These conditions are precisely where purpose-built tooling has the most to contribute.
Understanding Legacy Code with AI
Technical debt is what accumulates when extension outpaces maintenance.
Across long-running projects, that debt is often invisible. Logic added years ago by engineers no longer on the project carries no documentation. Dependencies introduced as workarounds exist in the source but not in any written record.
Modules that appear unused but remain load-bearing are never flagged reliably by manual review.
AI tools surface what manual review would take months to map. Hidden dependencies are traced by analyzing which modules reference which functions across the full repository. Undocumented logic is identified by comparing actual behavior against structural patterns. Buried relationships between modules become visible before a single change is proposed.
What the analysis produces is not a list of problems. It is a dependency map: which parts of the product are connected and how those connections operate. Where a change in one place produces an effect somewhere else, the map makes that visible. For engineering leadership, that map is the foundation of any credible modernisation plan.
The alternative is discovering those dependencies mid-migration. A change applied without that context breaks functionality in a module the team did not know was affected. AI-assisted mapping eliminates that class of failure before it occurs.
Incremental Refactoring vs. Full Rewrites
Two approaches exist for addressing a legacy system: modernise it gradually or replace it entirely. Both are defensible in the right circumstances. The trade-offs are significant and asymmetric.
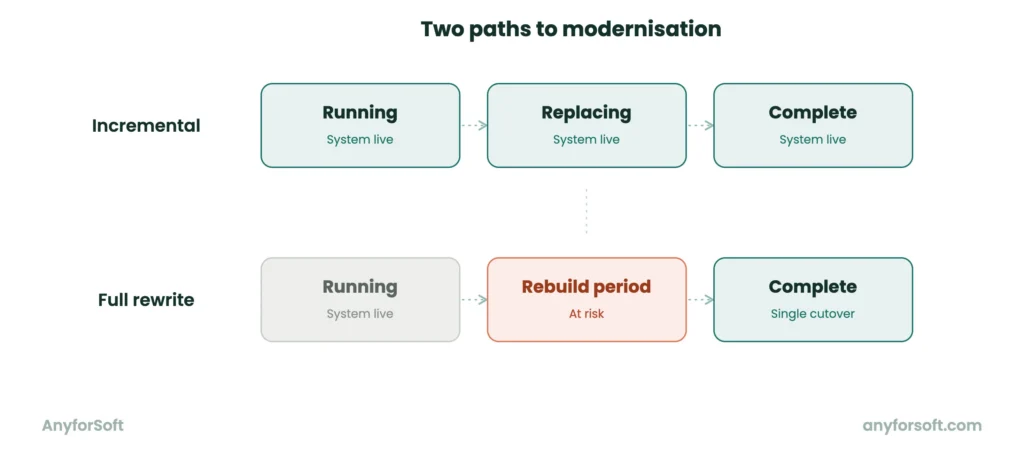
A full rewrite replaces the existing solution with a new one built against current standards. The appeal is a clean slate. The risk is real: the existing app continues to serve users and generate revenue while the new one is being built. Change requests accumulate on both sides simultaneously. That parallel operation is expensive and rarely goes as planned.
A different path is what the Strangler Fig pattern offers. Named after a vine that grows around an existing tree, it involves building new functionality alongside the running version.
Traffic is redirected incrementally as the modern version matures. The original version shrinks as the modern one grows. The existing functionality remains available at every stage of the migration.
Incremental modernisation through this approach carries lower risk at every stage. Each change is bounded, testable, and reversible. Progress is visible without requiring the full migration to be complete before value is delivered.
In most modernisation contexts, this is the safer default.
LLM-Assisted Documentation Generation
One of the most persistent obstacles is what LLM-assisted modernization directly addresses: the absence of documentation. For a broader treatment of what this means in practice, legacy application modernization covers the subject in depth.
In a system built over many years, documentation is rarely complete. Functions are added without docstrings. Architecture decisions are recorded in email threads, if at all. New engineers inherit a platform they must reverse-engineer to understand.
Large language models generate documentation directly from the existing source. A function is analyzed and its behavior is inferred from structure and context. A docstring is then produced describing what the function does and what it expects as input. What it returns is documented in the same pass. That process runs across the full repository, not just the sections under active development.
Architecture notes are generated at a higher level. A module serving a specific role in the overall structure receives a model-generated summary.
The summary names what the module does and why it exists.
Engineering teams use these summaries to orient new contributors and to support the dependency mapping described in the previous section.
The documentation produced is a starting point, not a final record. Engineers review and correct it.
What it replaces is the weeks of manual reading and annotation that inheriting an undocumented system otherwise requires.
AI Code Refactoring Best Practices
The tools matter. How they are introduced matters more. The practices below define what a controlled rollout looks like.

Always Refactor in Small, Testable Increments
The scope of each change determines how safely it can be validated. A change that touches one function can be tested in isolation. A change that touches twenty cannot.
Small, focused changes are the foundation of clean code. that standard requires every unit of logic to be readable and independently modifiable. Cascading effects from a single change are a signal that the scope was too broad.
In practice, this means defining a maximum scope before each session begins. One function or one class at a time. A well-scoped session produces four things:
- A defined scope — the change is limited to one function or class, with no adjacent modifications
- A clear before and after — the original state is recorded and the improved state is documented
- A validation baseline — tests confirm the output matches the original before the change proceeds
- A rollback point — if the change produces an unexpected result, the original state is recoverable
Large-scope changes feel efficient at the planning stage. In execution, they produce validation gaps that surface later, when the cost of correction is higher. Small increments are slower in isolation and faster in total.
Require Full Test Coverage Before AI Refactoring
Automated analysis improves structure.
Behavior verification is not part of what they do. That verification depends on tests that exist before the first suggestion is applied. Without them, there is no baseline to validate against.
Unit tests are the minimum requirement. A unit test checks that a single function produces the expected output for a given input. It then confirms that the refactored version behaves identically to the original. For sections with no existing unit tests, writing them first is not optional. It is what makes the process safe.
Coverage gaps are also information. A function with no tests is either untested by design or forgotten. Both conditions are worth resolving before structural changes are applied.
Review Every AI Suggestion — Don’t Auto-Merge
Every suggestion the tool generates is a proposal waiting for a decision.
Every proposal passes through a human engineer before it is applied. No exception applies for simple changes. Familiar patterns are not exempt either.
The reason is not distrust of the tool. It is the nature of context. A suggestion may improve structure without breaking any test. It may still conflict with an architectural decision made six months ago. That decision lives in the engineer’s knowledge, not in the analysis.
Auto-merge removes the checkpoint where that knowledge is applied. Once removed, context-blind changes can only be caught after they have affected the main application. Review before merge is the cheaper intervention.
Use AI for Detection, Humans for Architectural Decisions
Detection and architectural judgment are not the same capability. What deviates from established patterns is what the toolchain surfaces.
Why a deviation exists is outside their scope.
Architectural decisions carry business context. Which services communicate and how data moves between them reflect constraints the tool has no access to. Applying AI suggestions to those boundaries without human review produces cleaner structure and riskier behavior simultaneously.
The boundary is clear in practice. A change affecting how a module is called or how data moves between services is an architectural decision. Everything else is a candidate for AI-assisted improvement.
Track Metrics Before and After (Code Coverage, Complexity, MTTR)
Without measurement, structural work is an expense. With it, the same work becomes an investment.
Without a baseline recorded before the first change, there is no evidence of improvement. Where further work is needed cannot be determined either.
Coverage is the first metric to track. It measures what percentage of the application is exercised by tests. A rising score confirms the work expanded the testable surface.
Cyclomatic complexity measures how many independent paths run through a function. A falling score confirms the structure is simplified.
A persistently high score signals that further work is warranted.
MTTR, or mean time to recovery, measures how quickly the system recovers from a failure. A falling score confirms the changes made diagnosis faster. That improvement becomes visible in incident response data over time.
Taken together, these metrics reflect software maintainability: how much engineering effort the application requires to keep running and evolving. For organizations treating that as a long-term investment, software maintenance and support covers how that effort can be structured.
Why Teams Choose Anyforsoft for AI-Assisted Code Refactoring
When AI for code refactoring produces consistent results, three conditions are usually in place: the engineering is precise, the toolchain is current, and the team understands what automation cannot do. Those three conditions are what Anyforsoft brings to each engagement.
AI-First Engineering Approach
There is a difference between engineering an intelligent system and configuring one off the shelf. At AnyforSoft, that distinction shapes how every project is scoped.
For FilterSync, the team built a Python-based AI verification module from scratch, including a human-in-the-loop escalation layer for edge cases automation alone could not resolve.
A custom multi-LLM prompting architecture, built for Newser, produced a 25% increase in daily content output while preserving editorial quality. In both cases, the artificial intelligence layer was engineered around a specific problem, not selected from a catalog.
That precision is where engineering velocity becomes measurable. Fewer assumptions in the design phase mean fewer corrections mid-build. Structured around this principle, code quality services follow a defined sequence — detection, scoping, and implementation — where each stage informs the next.
Full-Cycle Code Audit and Refactoring
Structural improvement without a prior audit is a common source of incomplete results. Structural problems that are not mapped before work begins surface mid-engagement, when the cost of addressing them is higher. Before every engagement at Anyforsoft, a structured tech health check establishes what exists, what carries risk, and what the realistic scope of improvement is before a single change is proposed.
For CYBEX, the engagement began with a full assessment of accumulated legacy JavaScript. Only after that scope was understood did the team proceed, rebuilding from scratch on Drupal 9 and achieving green scores across all PageSpeed Insights metrics.
Without the audit, the rebuild would have carried the same structural risks as the original. The audit made the outcome predictable.
Legacy Modernisation Experience
Structural problems that require this kind of intervention rarely appear overnight. They accumulated.
Experience is what this inheritance demands most.
In software modernization engagements, Anyforsoft’s depth is most visible. For projektmagazin, 13,000 nodes and 13 content types were migrated from an end-of-life CMS with zero data loss, producing an 18% increase in traffic and a 31% improvement in site speed. The biggest contributors are maintenance burden and the engineering time that workarounds absorb over time.
For organizations considering software product development on a modernized foundation, this baseline matters.
Transparent Refactoring Roadmap and Backlog
An improvement engagement without a defined roadmap becomes a rolling scope. Changes accumulate, priorities shift, and the connection between engineering work and business outcomes grows harder to trace. Before implementation begins, Anyforsoft produces a roadmap that names what will be addressed, in what order, and what each stage is expected to deliver.
Predictable time to market follows from that structure. For Verifone, 30+ stakeholders, four coordinated teams, and tight delivery deadlines were all held together by a roadmap that did not shift under pressure. Delivery was on schedule. When the scope of the work is visible to everyone involved, decisions do not wait for alignment that should have happened earlier.
Flexible Engagement Models (Team Extension, Project, Retainer)
Not every engagement looks the same. Some organizations need a dedicated team embedded in their existing workflow for an extended period. Others need a defined project with a fixed scope and a clear endpoint. Still others benefit from an ongoing retainer that keeps structural quality improving incrementally over time.
For organizations not yet certain which model fits, IT consulting is available at the scoping stage. The engagement structure follows the nature of the problem. Accumulated debt across an aging system calls for different terms than a targeted sprint on a single module.
Across all three models, what stays consistent is the audit-first approach, the defined roadmap, and the human review layer that prevents automation from operating beyond its reliable scope.
FAQs
What is AI code refactoring and how does it differ from manual refactoring?
Using AI for code refactoring means applying machine learning and language models to detect structural problems automatically. Improvement suggestions are generated and targeted to specific sections of the source.
Without automation, a developer reviews the source line by line.
Across large or aging systems, that produces inconsistent results and competes with active development for engineering time.
Human review still determines whether each suggestion is applied. Detection and proposal are handled by the tool.
What types of code can AI refactor automatically?
The tools handle structural improvements that are discrete, bounded, and independent of business logic. Reliable candidates include:
- Dead code removal: functions never called, variables never used, dependencies serving no active purpose
- Duplication: repeated logic across modules that should exist in one place
- Naming: identifiers that no longer reflect actual purpose
- Function complexity: overly long or deeply nested functions that can be simplified
Architectural decisions and business logic changes fall outside reliable scope. So does anything requiring context the tool cannot access from the source alone.
Which AI tools are best for code refactoring in 2025–2026?
The right choice among AI code refactoring tools depends on where improvement needs to happen. GitHub Copilot and Cursor operate at the editor level. Amazon Q Developer fits AWS-heavy environments. Sourcery and Tabnine serve specific language stacks and team structures. CodeClimate sits alongside these as a complementary option, focused on maintainability metrics and technical debt tracking rather than inline suggestions. Stack, team size, pipeline configuration, and deployment environment all shape which combination works best.
How do I safely introduce AI refactoring into an existing codebase?
Start with an audit before any tool is configured. Apply changes in a safe branch first. Require test coverage for any section before suggestions are applied. Without a baseline, there is nothing to validate against. Review every suggestion before merging, and scope each session narrowly. One module at a time produces results that are testable and reversible.
Can AI refactor legacy code without full test coverage?
It can generate suggestions. Applying them safely without test coverage is a different matter. Among the best practices for AI refactoring of legacy code, a test baseline before any changes is the most critical requirement. Establishing it before the first session is what makes the process safe. In legacy environments specifically, behavior is often undocumented. Tests are the only reliable record of what the system is supposed to do
How do I validate that AI-suggested refactoring doesn't break functionality?
Three validation layers apply before any change reaches the main application:
- Automated tests: confirm the updated version produces identical outputs to the original
- Security scan: tools like Snyk check for vulnerabilities introduced or exposed by the changes
- Engineer review: each change is examined against knowledge of how the affected module is actually used in production
Structural improvement and behavioral equivalence are confirmed independently. Both conditions must hold before anything is merged.
What metrics should I track to measure AI refactoring impact?
Three metrics carry the most signal. Test coverage measures what percentage of the application is exercised by tests. Cyclomatic complexity measures independent paths through a function. A falling score confirms the structure is simplified. MTTR measures how quickly the system recovers from a failure. Recording baselines before the first session is what makes any of these figures meaningful.
What are the limitations of AI code refactoring?
Three boundaries define where automation stops being reliable. Architectural decisions carry business context the tool cannot access from the source alone. Business logic presents the same constraint. A rule that looks like a structural inefficiency may exist for a reason the tool has no visibility into. Incomplete context is the third limit: suggestions based on partial information may be structurally sound and operationally wrong. These boundaries are not failures of the technology. They are the reason human review remains non-negotiable.
How do large language models (LLMs) understand and transform code structure?
Large language models parse both syntax and semantics simultaneously. Syntax is how the source is written. Semantics is what it does and how its parts relate. That dual-level reading is what allows code refactoring AI to propose targeted transformations rather than generic fixes. The model infers the role of each function within the broader structure. That sensitivity to surrounding logic separates LLM-based suggestions from rule-based systems. The latter applies the same fix to every matching pattern, regardless of context.
What AI-powered tools automate code refactoring end-to-end?
End-to-end automation in AI-powered code refactoring connects detection, suggestion, pipeline integration, and validation in a single workflow. GitHub Copilot handles editor-level suggestions. Amazon Q Developer and Cursor operate at the repository and multi-file level. Claude Code enables end-to-end automated workflows at the command-line level, integrating directly with development environments to handle multi-step structural improvements. What these tools remove is the manual effort between stages. The judgment required at each one remains with the engineer.

