



Aging software drains engineering budgets, blocks integration with modern services, and leaves organizations dependent on a shrinking pool of specialists who understand it. Each year without a plan, the cost of maintenance grows. The window for a controlled transition narrows.
A structured legacy modernization strategy resolves those pressures by defining which applications to address, in what order, and through which approach. The range runs from software modernization programs that re-platform individual services to full digital transformation initiatives that rebuild the application portfolio from the ground up.
AnyforSoft has delivered modernization programs across industries. The list includes a full reconstruction of the Game Informer platform from an inherited codebase with no documentation. Another example is an ERP integration for CYBEX that eliminated legacy code blocking the platform’s performance.
The article covers the main modernization approaches, a step-by-step process for building a program, and the role of AI in accelerating delivery.
Each section includes practical guidance on the risks most likely to surface during delivery.
What Is Legacy Modernization?
Age alone does not make a solution legacy. An application becomes legacy when its architecture prevents the organization from changing it at the pace the business requires.
The scope of legacy system modernization is wider than replacing old code. It covers the architecture, data structures, integration patterns, and operational practices. A mainframe running payroll may be decades old and still serviceable. A five-year-old platform with no documentation and no test coverage may already be unmaintainable.
That distinction matters because it determines where the work begins. Organizations that treat system modernization as a technology upgrade tend to underestimate scope. Those that treat it as structural change to how software is built, maintained, and connected tend to plan and resource it more accurately.
At enterprise scale, legacy modernization rarely involves a single component. Most organizations carry a portfolio of applications in different states of decay, each with its own dependencies and risk profile. Some can be moved to the cloud with minimal change. Others require structural work before they can connect to modern infrastructure at all.
Legacy system modernization strategies define how an organization sequences and executes that work across the portfolio. The choice of strategy is not primarily technical. It is shaped by business continuity requirements and the level of risk the organization can absorb at each stage.
Why Legacy Systems Fail to Scale
Understanding what legacy modernization covers is the starting point. The more immediate question for most organizations is what staying on legacy software actually costs — not in abstract terms, but in concrete operational pressure. Five failure patterns account for most of that cost.
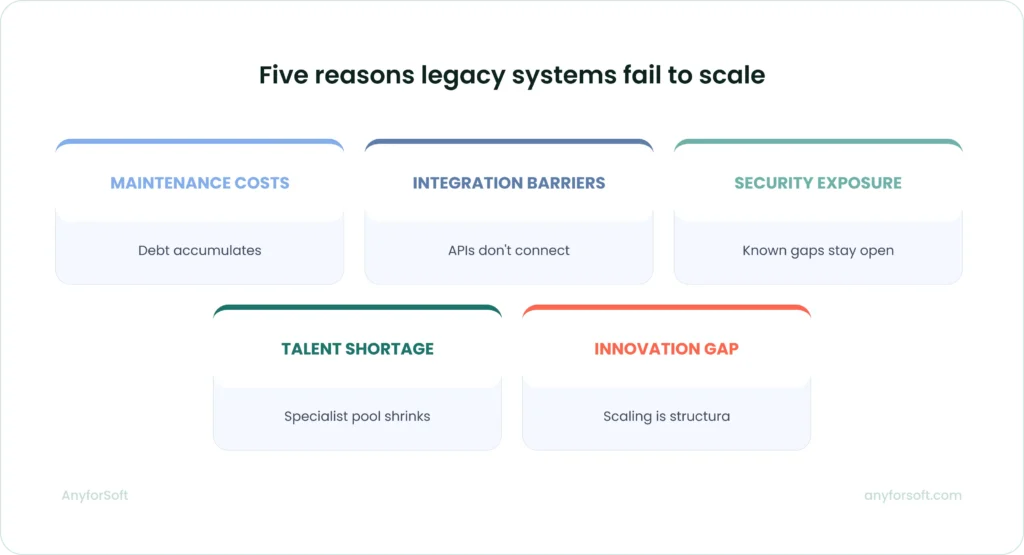
Rising Maintenance Costs and Technical Debt
Technical debt accumulates when development teams make expedient choices under time pressure. Those choices take predictable forms, such as shortcuts in architecture, undocumented changes, code that works but cannot be easily modified, and dependencies that were never mapped.
A single shortcut carries low immediate cost. Across years of production, without structural review, those choices compound into a system that requires disproportionate effort to change.
According to McKinsey’s 2023 analysis, technical debt accounts for approximately 40% of IT balance sheets. Companies pay an additional 10 to 20% on top of project costs just to address it.
The compounding mechanism is architectural. Each patch added without addressing the underlying structure raises the complexity of the next change. A codebase that started as a manageable set of modules becomes tightly coupled over time. Here, a change in one area breaks components in another. Regression risk increases with each release.
The consequence that matters most to the business is delivery speed. Teams working in heavily indebted codebases take longer to ship smaller changes. That slowdown is not a team performance problem. It is a structural one, and it does not improve while the debt remains.
Integration and Interoperability Barriers
Modern infrastructure expects tools to communicate through well-defined interfaces. REST APIs and event-driven architecture patterns all depend on services that can expose and consume data in standardized formats. Legacy platforms were not built with those expectations. They were designed to operate as self-contained applications, with integration as an afterthought.
The practical result is that every connection to a modern service requires a custom solution. An adapter, a middleware layer, a scheduled batch transfer, or a custom translation layer — each workaround solves one integration problem while adding to the maintenance surface.
Over time, the integration layer becomes complex and fragile.
The most common structural causes behind that fragility include:
- Point-to-point coupling
- Closed or undocumented interfaces
- Proprietary communication protocols
- Hardcoded data contracts between tools
None of these causes are straightforward to fix in isolation. Point-to-point coupling means that changing one set of features requires coordinating changes across every component it connects to directly. Proprietary protocols mean that no standard tooling applies.
The organizational consequence is integration paralysis. New vendors and data services arrive with modern interface expectations. A legacy architecture that cannot meet those expectations either blocks adoption of those services or requires significant custom engineering for each connection. It’s a cost that repeats with every new integration.
Security and Compliance Vulnerabilities
Unmaintained codebases accumulate exposure at a predictable rate. Vendors stop releasing security patches for software past its end-of-life date. Known vulnerabilities remain open. The software continues to run in production because replacement has been deferred, and the attack surface grows with each month it stays unpatched.
The compliance dimension compounds the security risk. Regulatory frameworks, inclusind PCI DSS, GDPR, HIPAA, and sector-specific equivalents, update on a faster cycle than legacy tools can accommodate.
A platform that was compliant at the time of its last major update may no longer meet current standards. The gap between what the application does and what the regulation requires widens without active remediation. Audit exposure increases proportionally.
For organizations in regulated industries, the combination carries direct financial and legal consequences. A breach originating from an unpatched legacy solution is not treated by regulators as an edge case. It is treated as a foreseeable failure to maintain reasonable controls. The cost of that finding typically exceeds the cost of the modernization that was deferred.
Talent Shortages for Obsolete Technologies
The engineer population with working knowledge of COBOL, older Java EE stacks, and proprietary mainframe environments shrinks each year. Most of that knowledge belongs to engineers approaching or past retirement age, and in the majority of programs Anyforsoft has assessed, it was never systematically documented or transferred.
The hiring market reflects that scarcity. Specialist contractors for COBOL and mainframe platforms command rates well above those of engineers working in modern stacks. Hiring timelines are longer and candidate pipelines are shallow. An organization that loses a key maintainer to retirement or departure cannot replace that person quickly, regardless of budget.
The deeper risk is institutional knowledge concentration. When understanding of a critical application exists in the memory of one or two individuals, that knowledge covers its undocumented behaviors, its edge cases, and its operational quirks. An application in that condition is a single point of failure. Emergency contractor engagement or accelerated modernization under pressure carries a higher cost than a planned program — in both financial and operational terms.
Inability to Support Digital Innovation
Scalability in a legacy context means more than handling additional traffic volume. The real test is whether the tool’s architecture can accommodate new business models, new data volumes, new integration requirements, and new deployment patterns without structural rework every time the business changes direction.
Legacy software typically fails this test not because they are slow, but because they were designed for a fixed set of conditions that no longer apply.
The cloud-native gap is the most visible expression of that constraint. Applications built for on-premises deployment were designed around persistent infrastructure, manual scaling, and direct app access. Cloud environments assume the opposite: elastic capacity, managed services, containerized workloads, and automated deployment pipelines. Moving a legacy application to the cloud without changing its architecture does not produce cloud-native capability. It produces a legacy application running on cloud hardware.
The innovation constraint shows up in delivery timelines. When a new product feature requires changes to a tightly coupled legacy platform, the blast radius of that change is wide. Testing is extensive. Rollback is complex. Release cycles stretch from weeks to months. Competitors operating on modern, modular architectures ship faster, with lower risk per release.
The data layer adds a further constraint:
- Real-time processing gap: Legacy batch-processing architectures cannot support products or features that require real-time data — personalization engines, fraud detection features, dynamic pricing models.
- Analytics readiness: Data locked in legacy formats and proprietary storage architectures is difficult to connect to modern analytics platforms, limiting the organization’s ability to act on its own operational data.
The architectural constraint does not resolve through increased investment. Additional development effort directed at a fixed architecture produces marginal gains. The ceiling is structural, and it does not move until the architecture does.
Core Legacy Application Modernization Strategies
Not every aging software requires the same response. Some should be retired. Others need structural rebuilding. A few are stable enough to leave in place while surrounding features are modernized. The range of approaches reflects that variety, from encapsulation, which wraps existing functionality behind modern interfaces without touching the underlying code, to full replacement.
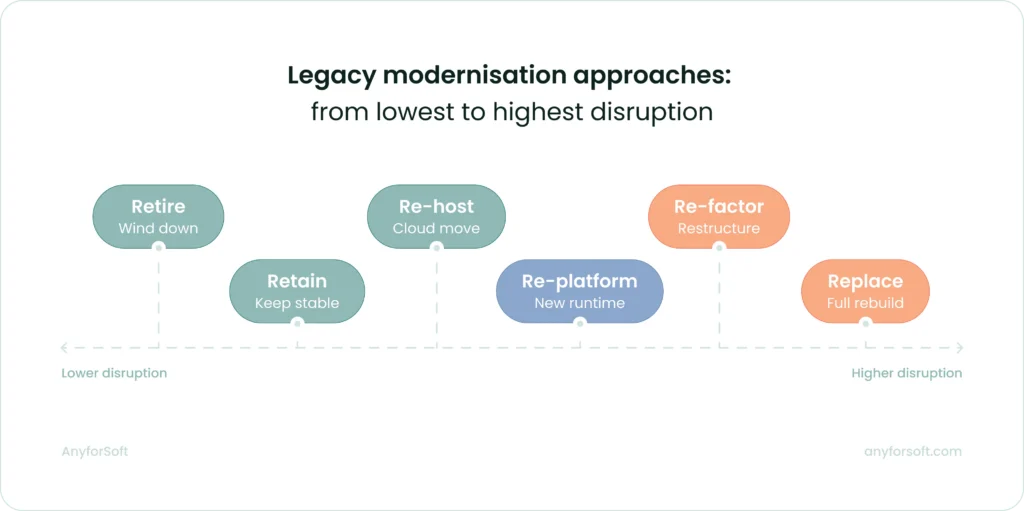
Retire — When Decommissioning Makes Business Sense
Retiring software means taking it out of production permanently. The solution and the business processes it supports are wound down entirely, with no migration and no replacement. Portfolio assessments that account for actual tool usage tend to surface more retirement candidates than teams expect. Assumed business value is a less reliable guide than usage data.
The case for retirement is strongest when software supports a function the organization no longer performs at meaningful scale.
- Redundant applications acquired through mergers and shadow solutions never formally decommissioned are common candidates.
- Tools built for discontinued product lines fall into the same category.
- So are reporting applications whose active user base has shrunk to a fraction of original volume. Keeping them in production consumes infrastructure and support resources for no operational return.
Decommissioning unused components shortens the dependency chain and reduces the blast radius of future changes. Each one removed from production reduces the coordination overhead the modernization program carries into subsequent phases.
Retain — When to Keep and Stabilise Existing Systems
Retaining means making a deliberate decision to keep it in its current state, with controlled investment in stability. It is a bounded commitment to maintain an app that is functioning adequately for a defined period.
Higher-priority units are modernized in parallel. Legacy modernization best practices treat retention as a timed decision.
The conditions that make retention the right call:
- Predictable, bounded workload: Transaction volume is stable, with no projected growth that would stress the current architecture.
- No active compliance gaps: Current regulatory requirements are met, with no trajectory toward non-compliance within the planning horizon.
- Limited integration exposure: Few connections exist to applications undergoing active change, which keeps the risk profile low during the modernization program.
- Documented codebase: At least one engineer understands the application well enough to maintain it safely, and that knowledge is not at immediate risk of departure.
Retention should be time-bounded. An application retained indefinitely without a defined review point tends to drift from managed stability into unmanaged neglect. The decision to retain should include a specific trigger at which the status is formally reassessed. That trigger may be a date, a compliance deadline, or a named business event.
Re-host (Lift and Shift) — Moving Without Redesigning
Re-hosting moves an application from its current infrastructure to a new environment, from on-premises servers to a cloud platform. It happens without changing the application’s code or architecture. The application runs in a new location. Its operational configuration, monitoring setup, and access controls are adapted to the new environment.
The primary driver is infrastructure cost and operational overhead. On-premises hardware requires physical maintenance and hardware refresh cycles. Moving that workload to a cloud provider eliminates those obligations and reduces the operational surface the internal team must manage.
For organizations with large on-premises estates, re-hosting workloads to a hybrid cloud environment reduces infrastructure operating costs. The reduction is proportional to the share of workloads moved and the gap between current hosting costs and cloud provider rates.
Re-hosting does not produce cloud-native capability. An application that was not designed for elastic scaling or managed services does not gain those properties by moving to the cloud. It runs on cloud infrastructure, but its architecture remains unchanged. The efficiency gains come from the infrastructure layer, not the application layer.
As a legacy modernization approach, re-hosting works best as a first phase in a longer program. It moves solutions off aging hardware quickly and creates time to plan more substantive modernization without the pressure of hardware end-of-life.
Re-platform — Minimal Changes, Major Infrastructure Gains
Application re-platforming makes targeted changes to an application so it can run effectively on a modern infrastructure platform. Altering the application’s core logic or architecture isn’t required.
The business functionality stays the same. In contrast, the operational layer changes. A Java application running on a physical server, for example, might be re-platformed by containerizing it with DOCKER and deploying it on a managed Kubernetes cluster. The application code itself is not rewritten.
Containerisation is the most common mechanism in re-platforming programs. It packages the application and its dependencies into a portable unit that runs consistently across environments and integrates with CI/CD pipelines. For apps where the architecture is not the primary constraint, re-platforming often delivers the best ratio of effort to outcome.
The operational gains it produces:
- Deployment consistency. DOCKER containers ensure the application runs identically across development and production environments. It eliminates environment-specific failures that slow release cycles.
- Managed infrastructure. Cloud-managed runtimes and databases shift patching and availability management to the provider, reducing the internal operational burden.
- Faster release cycles, Containerized applications integrate more naturally with CI/CD pipelines, which shortens the time between a code change and its deployment to production.
- Cost efficiency: Organizations that move from self-managed application servers to cloud-managed equivalents reduce the engineering time spent on infrastructure operations. That capacity is redirected to product work.
For platforms where the infrastructure is the constraint, re-platforming resolves the right problem. It does so without introducing the risk and cost of structural change.
Re-factor and Re-architect — Structural Modernisation
Refactoring improves the internal structure of existing code without changing its external behavior. Re-architecting changes how the solution’s components are organized and how they communicate. The two approaches address different layers of the problem and are often applied together in the same program.
Re-architecting addresses cases where the existing structure is the primary constraint on delivery speed and scalability. The most common direction is decomposing a monolithic application into MICROSERVICES, that are independently deployable services. Each of them is responsible for a bounded set of business functions.
In a monolith, every change requires a full regression cycle and scaling one function means scaling the entire application. Structural change produces the most durable return in solutions with that profile.
Both approaches carry higher execution risk than re-hosting or re-platforming and require sustained investment.
At enterprise scale, programs run from six to eighteen months depending on tool complexity and team capacity. A codebase that results from this work can be changed quickly and independently. That capability is proportional to the investment made in the structural work.
Replace — Full System Replacement and Migration
Replacing means decommissioning the existing application and building or procuring a new one to perform the same business functions. It is the highest-disruption option in the range of legacy application modernization strategies. This is also the one that carries the most execution risk at the program level. In specific circumstances, it’s also the most defensible decision.
Core system replacement is appropriate when the existing software cannot support the required business outcomes regardless of the modernization effort applied.
The conditions that warrant it:
- Proprietary platform with no viable migration path
- Vendor support discontinued with no upgrade route available
- Codebase degradation that makes re-architecting more costly than rebuilding, based on a structured effort assessment
- Compliance requirements cannot meet at the architectural level
Scope underestimation is the most common execution risk: the full set of business rules embedded in an outdated software is rarely visible until migration is underway. Data migration introduces integrity risk at every stage. The organization must also operate existing software and manage the replacement in parallel during transition. It creates operational complexity that must be budgeted and staffed explicitly.
The decision to replace should follow a structured assessment of the estate’s condition and the cost of alternatives. This assessment should establish that the required business outcome cannot be achieved through a less invasive approach. It should also confirm that the organization has the delivery capacity to execute a program of that scale.
How to Build a Legacy Modernization Strategy: Step-by-Step
Selecting the right approach for each application is one decision. Sequencing and executing those decisions across the full portfolio is another. Legacy system modernization strategies address both, and the order in which the program is built matters as much as the approaches it applies. The legacy modernization roadmap takes shape across the following stages, each conditioning the one that follows.
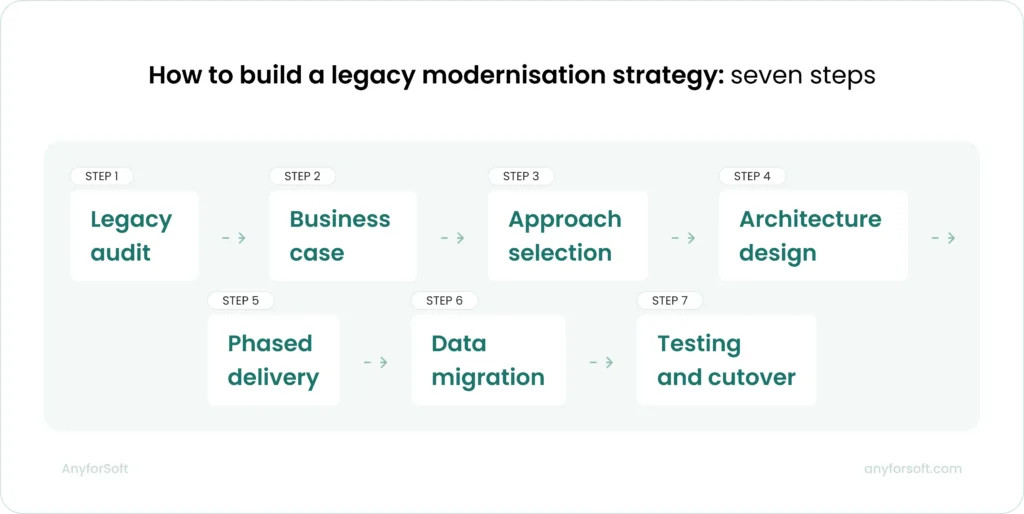
Step 1. Legacy Audit and Technical Debt Assessment
The audit is the first stage because every subsequent decision depends on an accurate picture of the existing estate. Without it, scope estimates are assumptions and prioritization defaults to organizational preference rather than technical evidence.
An enterprise architecture audit examines the codebase at the component level — what exists, how tightly coupled its dependencies are, and what technical debt has accumulated by type and severity. Automated scanning tools produce dependency graphs and complexity scores faster than manual review allows. That output becomes the factual baseline for every planning decision that follows: which applications suit which approach, where scope risks concentrate, and which dependency chains will surface as unplanned work if missed.
Step 2. Business Case and Prioritisation
The business case translates audit findings into financial and operational terms. It establishes the cost of inaction alongside the projected cost and timeline of the program.
Both figures are needed before any commitment is made. Applications that combine high business criticality with high technical risk rank first. The output is a ranked portfolio view — which applications to address, in what sequence, and through which approach — that serves as the governing document for the program. Scope changes during execution should require a formal decision against it, not an informal accommodation.
Step 3. choosing the right modernisation approach
No single approach fits every application.
The technical condition of the application defines what is feasible. An architecture that cannot be re-platformed without structural change removes some options. Within what is technically possible, the continuity requirement of the business process the application supports narrows the selection further. An approach that is technically sound but requires extended downtime on a revenue-critical process is not the right choice for that application, regardless of its engineering merits.
Step 4. Architecture Design and Technology Selection
An API-first architecture defines how components communicate before any individual component is built or migrated. Services expose well-defined interfaces, and new capabilities connect through those interfaces rather than requiring changes to the internals of the components they integrate with.
Technology selection follows. Kubernetes manages the deployment, scaling, and availability of independently deployable services at the infrastructure layer. The choice of runtime, database, and integration tooling follows from what the architecture requires — not from organizational familiarity.
The output of this step is a documented blueprint and a defined technology stack. Both are required before delivery begins.
Step 5. Phased Delivery and Risk Management
Each phase migrates a bounded subset of functionality, validates it against defined criteria, and establishes it as stable before the next phase begins. A failure in one phase can be contained without rolling back the entire program.
DevOPS practices are what make phased delivery operationally viable. Automated testing validates each change before it reaches production, and deployment pipelines remain consistent across environments. Without those capabilities, each phase transition becomes a manual, high-risk event rather than a controlled, repeatable process. That consistency is what allows the program to move quickly without accumulating transition risk at each stage boundary.
Step 6. Data Migration and Integration
Data migration and application integration are not independent workstreams. Records migrating from the source must be consumable by the interfaces the new architecture exposes through REST API. If the data structure does not conform to what those interfaces present, the migration fails at the point of consumption, not extraction.
Code migration maps field relationships between source and target schemas and transforms data into formats the new platform requires.
Extraction is validated before transformation begins. Transformation output is tested against a representative sample before the full dataset is processed. Programs that defer validation to the final stage accumulate errors that are expensive to resolve after cutover.
Step 7. Testing, Validation, and Cutover
Testing is distributed across the program, not concentrated at the end.
Each phase carries its own regression coverage, performance benchmarks, and data reconciliation checks, so the behavior of the new platform is well understood before cutover arrives. Infrastructure as code makes the transition repeatable — the environment is defined in version-controlled configuration files, provisionable identically across staging and production.
Operational efficiency at cutover is a direct consequence of having tested, defined infrastructure in place rather than manually built environments that diverge across stages.
AI and Automation in Legacy Modernisation
The volume of code, dependencies, and data that a modernization program must assess before making sound decisions has historically required months of manual engineering work. AI and automation tooling compresses that work without removing the judgment required to act on it.
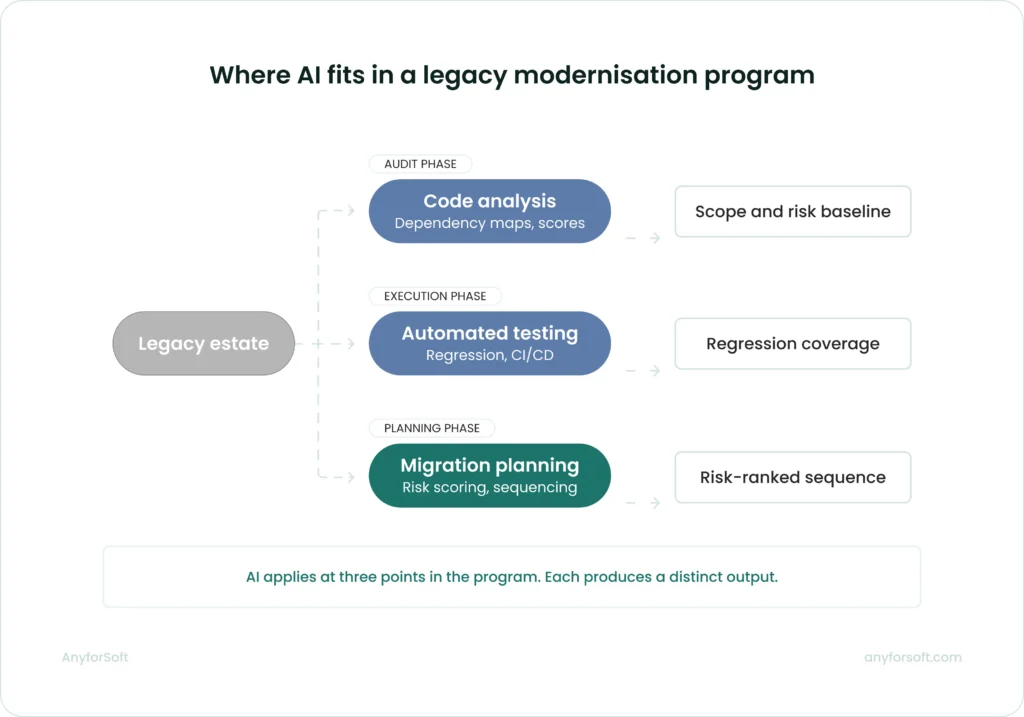
AI-Assisted Code Analysis and Documentation
Automated code scanning tools analyze existing codebases at a depth and speed that manual review cannot match. Where a team of engineers might spend weeks mapping dependencies in a large inherited application, scanning tools produce dependency graphs and complexity metrics in hours. That output becomes the factual basis for every subsequent planning decision.
LLM-assisted refactoring extends the analysis layer into code transformation. Large language models trained on code identify patterns of technical debt and suggest refactoring approaches. In some cases they generate refactored code directly. The engineer reviews and validates the output, which shifts the work from generation to judgment.
The gains that AI-assisted analysis produces at the code layer:
- Dependency visibility. Scanning tools surface undocumented connections between modules and external applications, producing a map that manual review would take significantly longer to construct.
- Complexity scoring. Each component of the codebase is assigned a complexity rating, which informs both the effort estimate and the sequencing of refactoring work.
- Documentation generation. AI tools generate inline documentation from existing code, making implicit application behavior explicit and reducing the knowledge concentration risk that aging codebases carry.
- Debt quantification. Technical debt is categorized by type and severity, giving the program team a prioritized view of where structural remediation produces the highest return.
Documentation is the layer where inherited codebases are most vulnerable. Engineers who understand an application’s behavior leave, and the knowledge leaves with them. AI-generated documentation reflects what the code actually does, not what it was intended to do when written.
Automated Testing and Regression Coverage
Modernization programs create significant regression risk. Every structural change to an existing codebase introduces the possibility that behavior which worked before no longer works the same way. Manual testing at the scale required to cover a large inherited application is time-consuming and incomplete by nature.
Automated testing integrated into CI/CD pipelines addresses that risk directly. Each code change triggers a test run that covers the defined regression surface before the change is merged. The feedback loop between a change and its validation shrinks from days to minutes. Teams move faster through structural changes because catching a regression early is inexpensive, and missing one in production is not.
What automated testing produces across a modernization program:
- Consistent regression coverage across every code change
- A documented test suite that remains in the codebase after the program closes
Intelligent Migration Planning and Risk Scoring
ML-based analysis applied to an aging estate does more than describe what exists. It identifies which applications carry the highest migration risk and which dependencies are most likely to cause failures during cutover. That output is risk scoring: a ranked view of the estate that grounds prioritization decisions in data.
AI-assisted migration planning uses that scoring to generate sequencing recommendations. The planning layer draws on codebase analysis and dependency mapping, supplemented by historical data from comparable programs. The recommendations update as conditions change during execution.
The causal relationship between better risk intelligence and program outcomes is direct. Programs that enter migration without a data-driven view of the estate encounter scope surprises mid-execution. Dependencies surface that were not mapped. Cutovers that appeared low-risk require rollback. Each unplanned event extends the timeline and increases cost.
Programs that apply ML-based risk scoring to sequencing decisions achieve faster time to market for their modernization outcomes. The efficiency gain comes from avoiding the delays that unmanaged risk creates. Fewer surprises in execution mean fewer unplanned stops.
Key Challenges and How to Overcome Them
AI tooling reduces the analytical burden of modernization planning. The execution challenges, however, remain organizational and technical in equal measure. Four failure patterns account for the majority of programs that run over budget or fall short of their original scope.
Underestimating Scope and Hidden Dependencies
The most common source of scope underestimation in modernization programs is monolith. A large, tightly coupled application accumulates business logic over years of development. Much of that logic is undocumented. It becomes visible only when a change breaks something unexpected.
Hidden dependencies compound the problem. An aging platform that appears self-contained often has undocumented connections to other applications and batch processes. Those connections surface during migration, not during planning, which is the worst point to discover them.
A structured dependency mapping exercise, supported by automated code scanning, produces a complete picture of the application’s connections and internal complexity. That picture is the basis for a realistic scope estimate. Programs that complete this step before committing to a timeline encounter fewer mid-execution surprises than those that proceed on assumed scope.
Organisational Resistance and Change Management
Modernization programs disrupt established working patterns. Teams that have built expertise in existing platforms face uncertainty about their role after the program closes. Processes that have been stable for years change. The resistance that follows reflects a reasonable response to disruption without adequate information about what comes next.
The programs that deliver on schedule treat change management as a delivery workstream. That means identifying the affected teams early in the program and involving them in decisions about how their workflows will change. Concrete training on replacement platforms should begin before the cutover date. Resistance addressed at the process level resolves faster and with less impact on delivery timelines.
Data Integrity During Migration
Data migration is the stage where integrity risk is highest. Records in the source application must arrive in the target accurately and consistently. They must also satisfy the business rules the new platform enforces. The gap between those two states is where data loss and reconciliation failures occur.
The conditions that produce integrity failures:
- Undocumented data transformations applied during extraction
- Field mapping errors between source and target schemas
- Referential integrity rules in the target that the source data does not satisfy
- Batch migration processes that are not validated against the source before cutover
The solution is a defined validation protocol applied at each stage of the migration pipeline. Extraction is validated against the source. Transformation logic is tested against a representative data sample before the full migration runs. The target is reconciled against the source after load. Programs that treat validation as a final step accumulate errors that are expensive to resolve after cutover.
Maintaining Business Continuity During Transition
Business continuity during a modernization program means that operational processes keep running at acceptable performance levels while the underlying platforms change. Programs that define continuity thresholds before migration begins are better positioned to contain the impact of issues that arise during cutover.
The most common failure pattern is a cutover planned as a single event. The entire existing application is replaced by the new one on a fixed date. If anything goes wrong during that cutover, the rollback path is complex and the operational impact is immediate. A single-event cutover concentrates all execution risk into one moment.
Phased delivery distributes that risk across the program timeline. Functionality is migrated in bounded increments, each independently testable and reversible if needed. The existing platform remains in operation for the functions not yet migrated.
The structural elements that make phased delivery work:
- Parallel operation. Both the existing and new platforms run simultaneously during each migration phase. Traffic switches to the new environment when defined criteria are met.
- Rollback definition. Each phase has a rollback procedure that is tested before the phase begins. It is not written in response to a failure during cutover.
- Incremental user migration. User cohorts move to the new platform in stages, which limits the operational impact of any issue discovered after go-live.
- Monitoring thresholds. Performance and error rate thresholds are defined before each phase begins. A breach triggers a defined response.
Each of these elements reduces the concentration of risk at any single point in the program.
How Long Does Legacy Modernisation Take — and What Does It Cost?
Risk distribution affects both timeline and budget. So do a set of variables that differ across every program. There is no fixed answer to either question, but the variables that drive the range are consistent and can be assessed before a program begins.
The factors that determine timeline:
- Estate size
- Dependency complexity
- Data migration volume
- Regulatory requirements
- Internal team capacity
Each variable shifts the range in a predictable direction. A larger estate with undocumented dependencies and a complex data migration will take longer than a bounded, well-documented application with a clean data structure. That relationship holds regardless of the modernization approach chosen.
Timeline ranges by program type give a working frame. A re-hosting program for a defined set of on-premises workloads runs from two to six months. An application re-platforming program, depending on the number of applications involved, runs from four to twelve months. Structural re-architecting programs at enterprise scale run from twelve to thirty-six months. Full core system replacement, including data migration and parallel operation, sits at the upper end of that range or beyond it, depending on the size of the estate and the complexity of the target platform.
Cost follows the same variables. The factors that increase cost:
- Undocumented dependencies. Each undocumented connection discovered during execution adds analysis, testing, and coordination work that was not in the original estimate.
- Data quality gaps. Source data that does not conform to the target platform’s requirements requires transformation work before migration can proceed.
- Parallel operation duration. Every month the existing and new platforms run simultaneously adds infrastructure and operational support cost that scales with the size of the estate.
- Regulatory validation requirements. Regulated industries require formal validation of migrated data and platform behavior, which adds testing cycles and documentation overhead.
Cost reduction is the financial outcome that modernization programs most commonly target. The reduction materializes across infrastructure operating costs, engineering maintenance hours, and the elimination of licensing fees for platforms that are no longer in use. Those gains do not appear immediately. They accumulate as migrated workloads stabilize on the new platform and the old infrastructure is decommissioned.
The MVP approach shortens the time to first return. Rather than migrating the full estate before any benefit is realized, the program identifies the subset of functionality that delivers the highest business value and migrates that first. The remaining scope follows in subsequent phases. This approach compresses the gap between program start and the point at which the organization begins to see cost reduction and capability gains from the modernized platform.
Governance over scope is the most effective cost control available to a modernization program. Scope that expands during execution, driven by stakeholder additions or discovered complexity, is the primary cause of budget overruns. Programs that define scope boundaries before execution begins and maintain a formal change process for additions to that scope consistently deliver closer to their original estimates than those that do not.

Why Enterprises Choose Anyforsoft for Legacy Modernisation
Choosing the right IT services company for a modernization program is a consequential decision. The technical complexity is high, the execution risk is real, and the cost of a failed program exceeds the cost of a well-resourced one.
Anyforsoft approaches each engagement as a legacy modernization strategy problem first and a technical problem second.
What follows describes how that commitment translates into delivery.
Deep Enterprise and Domain Expertise
Domain knowledge in legacy modernization comes from having worked across the full range of inherited conditions. Anyforsoft has delivered programs on end-of-life platforms, deeply coupled codebases, and estates where documentation did not exist. That includes environments with mainframe-adjacent infrastructure, ERP modernization programs where live business processes could not be interrupted, and platforms where the original engineering team was no longer available.
The practical consequence is pattern recognition at the planning stage. The delivery team identifies failure modes before they become program events, including undocumented dependencies, data integrity gaps, and scope underestimation at the architecture layer. Each of those patterns has appeared in prior programs and was resolved there. That record shortens the time between discovery and a scope estimate the program can be held to.
Domain depth also means understanding the business context behind the technical condition. A payment processing platform with 14 billion annual transactions carries different continuity requirements than a content platform. An educational institution operating across multiple regions carries different compliance obligations than a commercial enterprise.
The modernization approach is shaped by those differences.
AI-First Engineering and Tooling
Generative AI tooling is embedded in the engineering process. It is applied at the code analysis layer, where it surfaces dependency maps and complexity scores from inherited codebases faster than manual review allows. It also generates documentation from existing code, reducing the knowledge concentration risk that aging platforms carry. Finally, it supports refactoring recommendations and automated test coverage generation across the codebase.
The delivery impact is visible at the program level. Analysis phases that previously consumed weeks of manual engineering work are completed in days, with a more complete picture of the estate. The time recovered at the analysis layer is redirected to architecture design and execution planning, which are the stages where program quality is determined.
End-to-End Delivery — From Audit to Production
Legacy modernization consulting and custom development are part of the same engagement at Anyforsoft. The team that maps the estate in the audit phase is the team that executes the migration, so the context built during assessment carries directly into delivery without translation loss.
What that arc covers in practice:
- Audit and dependency mapping. The inherited codebase is scanned, dependencies are documented, and technical debt is quantified by type and severity before scope is committed.
- Architecture design and technology selection. The modernization approach is selected against the audit findings, the organization’s continuity requirements, and the available delivery capacity.
- Phased migration and data validation. Migration runs in bounded increments, each validated against the source before the next phase begins.
- Production cutover and stabilization, The cutover procedure is defined and tested before execution. Post-cutover stabilization is part of the engagement scope.
The Game Informer case illustrates what that delivery capacity produces under pressure.
Anyforsoft inherited a partial codebase with no user data and no documentation. Revenue systems had to be rebuilt from zero and the platform had to go live under a fixed deadline, with a 28-year brand reputation at stake.
At relaunch, 5 million visitors hit the platform simultaneously and the infrastructure held.
The platform reached 26,000 subscribers from zero. When a promotional campaign required discount functionality during the relaunch period, the feature was delivered within 24 hours.
Proven Risk Management Methodology
RISK MITIGATION in a modernization program is most effective when it is structural rather than reactive. Anyforsoft builds risk controls into the program design before execution begins, not in response to events that occur during it.
Each program phase carries a defined rollback procedure, tested before the phase begins. Dependency mapping is completed before scope is committed. Data validation runs against the source before migration proceeds. Cutover criteria are defined in advance, so the decision to proceed or hold is based on measured conditions rather than judgment under pressure.
The projektmagazin migration demonstrates what that methodology produces at scale.
The platform was running on Drupal 6, which had reached end-of-life and stopped receiving security updates. The migration covered 13,000 nodes and 13 content types. Custom migration tooling was built to convert data into formats the new environment could process. Content integrity was preserved across the full dataset with no loss.
The platform has been in continuous operation since, with Anyforsoft providing ongoing maintenance and support.
Flexible Engagement Models
Organizations arrive at modernization programs with different internal capacities, different timelines, and different levels of risk they can absorb. The engagement model should reflect those differences. A structure that does not match the organization’s actual capacity and readiness produces friction between what the program requires and what the team can deliver.
Anyforsoft operates across three engagement models, each suited to a different organizational context. OUTSOURCING transfers full delivery responsibility to the Anyforsoft team, which is appropriate when the organization lacks internal modernization capacity or needs to contain execution risk within a defined contract.
A DEDICATED TEAM extends the organization’s internal capability with Anyforsoft engineers who work within the client’s processes and tools, which suits organizations that have delivery capacity but need specialist modernization experience to fill specific gaps.
A consulting partnership positions Anyforsoft as a modernization partner at the architecture and planning layer, with the organization’s internal engineers executing against the defined approach.
The IT modernization strategy an organization adopts determines which model fits. A program that requires full external delivery from audit to production calls for a different structure than one where internal engineers are capable of execution but need architecture guidance. Anyforsoft assesses that fit at the start of each engagement and structures the relationship accordingly.
FAQs
What is a legacy modernization strategy and why does it matter?
A legacy modernization strategy is the plan an organization uses to move aging software toward platforms that meet current operational demands. It defines which applications to address, in what order, and through which approach.
Maintenance absorbs an increasing share of engineering budgets as inherited platforms age. Integration with modern services grows more expensive with each workaround added, and the pool of engineers who maintain older stacks shrinks each year. Each pressure is manageable in isolation. Together, they form a cost structure that becomes harder to reverse the longer modernization is delayed.
How do you assess which legacy systems need to be modernised first?
Legacy system modernization priority is determined by four variables, including business criticality, technical risk, integration dependency, and modernization complexity. Systems that are both business-critical and technically degraded rank highest in the priority order.
Dependency mapping runs alongside that assessment. A platform that appears stable in isolation may be at the center of a dependency chain that affects every subsequent modernization decision.
Usage data is the third input. Applications whose active workload has dropped to a fraction of original volume are retirement candidates. Removing them early simplifies the dependency picture for every application that remains in scope for the modernization program.
What are the main approaches to legacy modernisation?
Legacy application modernization strategies fall into six categories: retire, retain, re-host, re-platform, re-factor and re-architect, and replace. Most programs use two or three in combination across the estate.
Legacy system modernization strategies are selected based on audit findings for each application, not applied uniformly across the estate. A platform with sound business logic but aging infrastructure may be re-platformed without touching the application code. Where the architecture itself is the constraint on delivery speed, re-architecting produces the more durable return. An application supporting a discontinued business function is a retirement candidate.
How long does a legacy modernisation project typically take?
Timeline depends on approach, estate size, and dependency complexity. Re-hosting runs from two to six months. Re-platforming from four to twelve. Re-architecting at enterprise scale from twelve to thirty-six. Full replacement runs from eighteen to forty-eight months or beyond.
The variable that most commonly extends timelines is undiscovered scope: hidden dependencies and undocumented business logic that surface during execution and add unplanned work.
What is the typical cost of legacy modernisation?
Cost follows the same variables as timeline. Re-hosting or re-platforming a single application runs from $50,000 to $250,000. A mid-size re-platforming or re-architecting program runs from $250,000 to $1,500,000. Enterprise-scale programs run from $1,500,000 to $10,000,000 and above.
The MVP approach reduces time to first return by migrating the highest-value functionality first, so the modernized portion of the estate begins generating cost reduction while the remainder of the program is still in execution.
How do you ensure business continuity during the modernisation process?
Business continuity is protected through phased delivery and parallel operation. Functionality is migrated in bounded increments while the existing application remains in operation for functions not yet migrated, limiting the impact of any issue discovered after go-live.
Each phase carries a rollback procedure tested before the phase begins. Cutover criteria are defined in advance, covering performance thresholds and data reconciliation checks. The decision to proceed is based on those measured conditions, not judgment under pressure.
For organizations in regulated industries, both platforms must satisfy regulatory requirements simultaneously during parallel operation, which adds a validation layer to each migration phase.
What risks are most common in legacy modernisation — and how do you mitigate them?
The most common risks are scope underestimation, data integrity failures during migration, and organizational resistance to changed workflows. A structured legacy modernization strategy builds controls for all three into the delivery methodology before execution begins.
Scope underestimation is mitigated through dependency mapping and automated code scanning completed before scope is committed. Data integrity risk is addressed through validation at each pipeline stage. Organizational resistance is reduced by involving affected teams early and beginning platform training before the cutover date.
Should we modernise incrementally or replace the system all at once?
Incremental modernization distributes execution risk across the program timeline. Each phase is independently testable and reversible, and the organization continues operating on the existing platform for functions not yet migrated.
Full replacement is appropriate when the existing architecture cannot support required business outcomes regardless of the effort applied. That condition is met by a degraded codebase, discontinued vendor support, or compliance requirements the platform cannot meet structurally.
The two approaches are not mutually exclusive. A replacement program can be executed incrementally, migrating bounded sets of functionality in sequence.
How is AI used in legacy modernization strategy today?
AI-powered modernization applies at three points: code analysis, automated testing, and migration planning. At the code analysis layer, AI tools produce dependency maps, complexity scores, and documentation from existing code faster than manual review allows.
Intelligent automation in testing generates regression coverage integrated with CI/CD pipelines, so each structural change is validated before it is merged.
Together, these capabilities increase the accuracy of scope and risk estimates that govern a Legacy modernization strategy. engineering time shifts from generating analysis to directing it, which is where program quality is determined.
Can AI tools help analyse legacy code and accelerate migration planning?
AI-assisted code scanning surfaces dependency chains and technical debt distribution across an inherited codebase in a fraction of the time manual review requires. That output becomes the factual basis for a scope estimate that holds through execution. When hidden complexity surfaces mid-program, the impact is contained rather than program-defining.
Predictive risk scoring ranks applications and migration sequences by failure probability. Developer productivity increases because engineers spend less time on manual analysis and more time on architecture decisions and execution planning.


