



Technical debt rarely announces itself through a major outage. Release cycles slow down first. Small engineering shortcuts begin shaping delivery speed, maintenance effort, and software maintainability long before systems visibly fail.
Over time, the economics change as well. Teams spend more hours working around earlier decisions, testing takes longer, and routine updates become harder to ship without added coordination. The result is a steadily growing total cost of ownership that affects both engineering capacity and business planning.
At AnyforSoft, we have worked on modernization and platform evolution projects across education, fintech, and AI-enabled systems, including:
- Imperial College Business School
- Wittenborg University of Applied Sciences
- Verifone
The Verifone platform supports localized experiences across more than 20 languages. That level of scale increases the pressure on infrastructure, governance, and long-term maintenance decisions.
This guide breaks the problem into practical stages. You will see how teams identify these patterns, prioritise remediation work, strengthen engineering practices, and reduce the risk of recurrence over time
Types of Technical Debt
Rarely does technical debt emerge in a single, isolated form. Some issues stay close to the codebase and affect daily engineering work almost immediately. Others spread across architecture, infrastructure, testing workflows, or deployment processes, gradually reshaping how the entire delivery pipeline behaves.
The Four Main Types of Technical Debt

Code Debt
Under delivery pressure, small shortcuts tend to accumulate quietly. Logic gets duplicated instead of extracted into reusable components. Temporary fixes remain in production longer than expected, while naming conventions drift as more contributors modify the same application over time.
The early signs stay close to individual tasks. A developer spends extra time tracing dependencies between files. Elsewhere in the codebase, an older feature becomes risky to modify. Fragile implementation logic has already spread across the components that depend on it.
Once these local workarounds begin repeating across the application, the symptoms become easier to recognize. Recurring code smells start shaping the pace of future engineering work. Deeply nested conditions, oversized classes, inconsistent abstractions, and hardcoded behavior make even routine updates harder to validate without regression risk.
Eventually, the problem expands beyond the code itself. Verification cycles grow longer and debugging consumes larger portions of each sprint. Teams begin avoiding unstable parts of the application unless changes become unavoidable.
A similar pattern emerged during AnyforSoft’s work for Imperial College Business School. The team addressed duplicated logic and fragile components directly, replacing temporary workarounds with cleaner, reusable structures. That work reduced the overhead required to modify the codebase and gave future contributors cleaner entry points for ongoing development.
Architectural Debt
Some structural problems extend beyond individual files or isolated implementation choices. architectural debt develops when core structural decisions begin constraining how the entire platform evolves over time.
Pressure from these constraints rarely surfaces as a single failure. A new feature requires coordinated changes across tightly coupled services. An integration that should take days expands into weeks because existing dependencies were never designed for flexibility.
As these constraints accumulate, future modifications become disproportionately expensive. Platform layers grow harder to separate cleanly. API boundaries become inconsistent, and DESIGN DEBT starts affecting both internal workflows and user-facing behavior.
Common warning signs include:
- Tight service coupling
- Fragmented API structure
- Repeated integration work
- Rigid deployment paths
Eventually, the issue stops being local to a single engineering task. Delivery planning becomes harder because even moderate updates carry broader system impact. Teams begin spending more time evaluating architectural risk before implementation work can begin.
That structural pressure shaped part of AnyforSoft’s modernization work for Imperial College Business School. The team addressed service coupling and API inconsistencies directly. Platform components were updated in a way that kept future changes within predictable boundaries. Reducing that structural overhead was a defined goal of the engagement from the start.
Test and Documentation Debt
Not all accumulated engineering risk appears directly inside production code. Test debt and documentation debt often accumulate quietly around the delivery process itself.
Outdated specifications, sparse inline documentation, and incomplete unit tests make systems harder to understand with confidence. Over time, developers begin relying more on assumptions, tribal knowledge, or manual verification during release preparation.
The consequences show up as hesitation before they show up as failure. Debugging takes longer because expected behavior is unclear. Onboarding slows as undocumented decisions accumulate, and release cycles become more stressful once reliable validation coverage starts disappearing.
Under those conditions, even small updates require additional caution. Teams spend more time confirming what the system should do before modifying how it works.
Dependency and Infrastructure Debt
Dependency debt and infrastructure debt accumulate through technologies that continue operating long after they should have been upgraded, replaced, or removed. Deprecated APIs, unsupported libraries, and aging deployment tooling often remain invisible during normal operations. A larger migration is usually what surfaces them. Outdated server environments follow the same pattern, drawing attention only when a security issue makes them impossible to ignore.
The platform continues operating without visible disruption. Compatibility problems begin surfacing between services. Upgrade paths narrow, and deployment workflows become harder to sustain consistently across environments.
Typical operational pressures include:
- Deprecated APIs. Integration updates start requiring additional workaround logic.
- Unsupported libraries. Security fixes and compatibility patches become harder to apply without regression risk.
- Aging pipelines. Deployment coordination slows as tooling drifts further from current standards.
- Server configuration drift. Environment inconsistencies begin affecting release stability.
As the surrounding ecosystem evolves, older dependencies create additional operational exposure. Keeping that infrastructure current starts consuming engineering capacity that could otherwise support product development. Tools such as Dependabot help teams surface outdated dependencies automatically before those risks expand further.Large-scale enterprise platforms make these pressures especially visible. During AnyforSoft’s work for Verifone, the platform spanned multilingual infrastructure, complex integrations, and caching layers across a broad technical environment. Keeping that system stable required careful long-term maintenance decisions at every layer.
Why Reducing Technical Debt Matters
Different categories of accumulated shortcuts create different engineering problems, yet the business consequences often converge in the same place. Release cycles slow down. Maintenance effort expands, and product teams lose flexibility long before systems fail outright

Teams that are actively managing technical debt usually detect those shifts earlier. Others continue adding new functionality while hidden delivery friction keeps accumulating across sprints.
The early losses appear contained. A feature takes several extra days to validate. An infrastructure issue delays deployment unexpectedly. Engineers start spending growing portions of each sprint working around older implementation constraints, with less capacity left for new development.
Across sprints, those delays compound into measurable operational cost. Developer velocity drops because more engineering hours move toward debugging, regression checks, coordination work, and repetitive upkeep. As lead times expand, time to market becomes harder to predict for both internal stakeholders and customers.
Effective tech debt management usually focuses on reducing recurring delivery friction before larger modernization work becomes unavoidable. Common business effects include:
- Longer onboarding periods. New engineers require more time to understand fragile or poorly documented systems.
- Slower release preparation. Validation and regression testing expand as confidence in existing behavior decreases.
- Increased support workload. Older infrastructure and unstable integrations generate additional operational overhead.
- Delayed feature delivery. Engineering capacity shifts away from roadmap execution toward maintenance and troubleshooting.
- Higher coordination cost. Teams spend more time evaluating implementation risk across interconnected platform components.
As these patterns spread across infrastructure and architecture, operational stability becomes harder to maintain. Security exposure increases once outdated dependencies stop receiving reliable updates. System reliability, in turn, gradually weakens under growing operational pressure.Under those conditions, even routine updates start carrying broader business risk. That is why long-term software maintenance and support work matters beyond bug fixing alone. Stable delivery requires continuous attention to maintainability, infrastructure health, and controlled platform evolution over time.
How to Reduce Technical Debt: Step-by-Step Guide
Reducing technical debt works best as a structured operational process applied gradually over time. The steps below create a practical sequence teams can follow without disrupting ongoing product delivery.
Technical Debt Reduction Flywheel

Step 1. Audit and Identify Existing Debt
Before work begins, teams need a clear picture of what they are dealing with. Accumulated shortcuts often remain fragmented across services, workflows, infrastructure, and undocumented engineering decisions. Nobody sees the full scope until a structured review begins.
Most audits combine four investigation methods:
- Static analysis scans
- Manual codebase walkthroughs
- Infrastructure reviews
- Engineering team interviews
The audit collects problems and builds context around each one. The goal is to understand how each issue affects release speed, upkeep effort, operational risk, or future platform evolution.
Once the findings become structured, debt prioritization becomes far more reliable. Cataloguing issues without ranking them usually creates another backlog. That backlog becomes difficult to manage consistently as it grows.
This early discovery work overlaps naturally with broader software product discovery activities. Both processes focus on identifying structural constraints before larger implementation decisions begin.
Step 2. Classify and Prioritise by Impact
The highest-risk items usually share one characteristic: they affect wide portions of the release lifecycle at the same time. A fragile integration may slow releases and increase support effort. Exposure grows long before the issue becomes visible to stakeholders outside engineering.
Resolution decisions benefit from a consistent evaluation framework. Teams typically assess each item against four practical criteria:
- Business impact
- Blast radius
- Remediation effort
- Delivery risk
Technical Debt Prioritisation Matrix
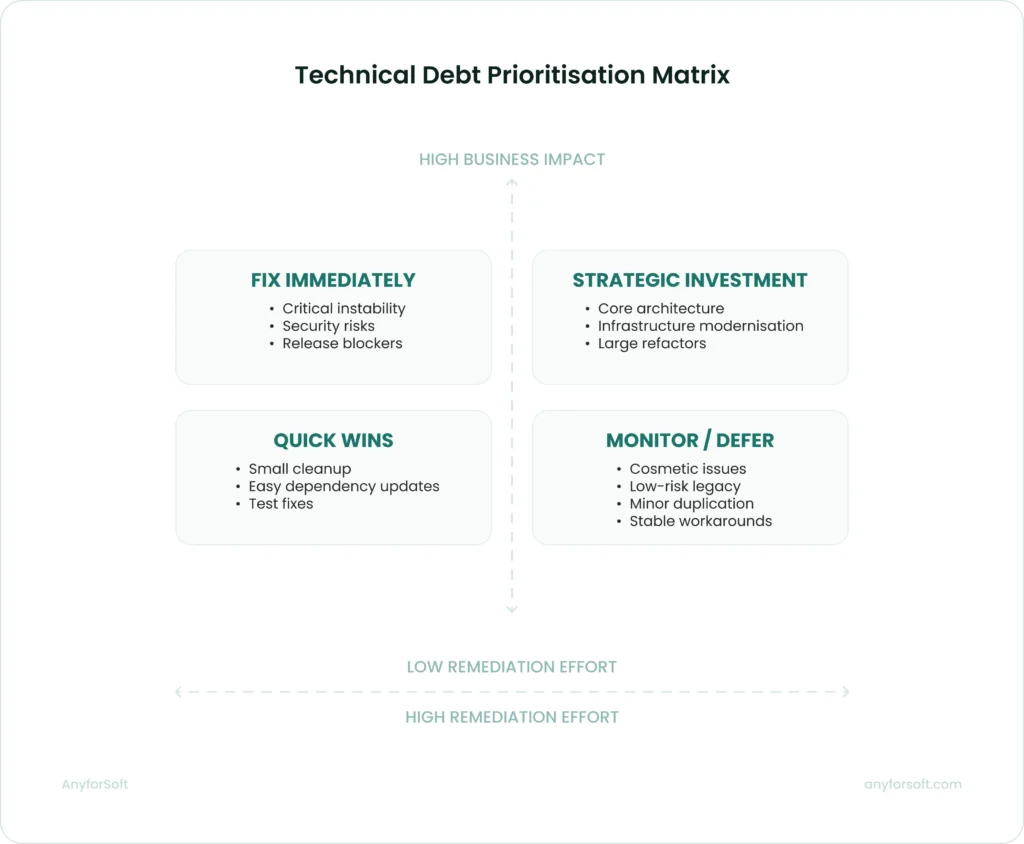
Once the audit results become structured, debt prioritization becomes far more practical. Lower-impact issues may stay inside the backlog temporarily, while high-risk items move into active planning discussions earlier.
In Agile environments, prioritized entries eventually flow into backlog grooming alongside product work. That process helps engineering and product teams evaluate tradeoffs using the same context. Accumulated issues no longer remain isolated from roadmap planning.
Step 3. Build a Technical Debt Register
A useful tech debt register typically contains four core elements: severity, ownership, estimated resolution effort, and a documented approach. Without that structure, teams often lose track of issues once discussions move beyond the initial audit phase.
A lightweight register is enough to start. A shared spreadsheet or backlog view can capture the most urgent items. The process can become more formalized as it expands across teams or services.
As the number of tracked items grows, centralized tooling becomes more important. Engineering teams use JIRA to manage entries across sprints. Ownership, progress, and planning remain visible inside the same workflow environment.
The register requires ongoing attention. Once entries stop reflecting the current state of the codebase, decisions begin relying on incomplete information again.
Step 4. Allocate Dedicated Remediation Time
Without protected sprint capacity, this work gradually disappears behind feature pressure. Urgent roadmap commitments almost always win short-term prioritization discussions unless time is intentionally reserved.
Most teams solve this by committing a fixed percentage of each sprint to upkeep and resolution work. In practice, the allocation often falls between 10% and 20% of total capacity. The exact percentage depends on codebase condition and release pressure.
Common allocation approaches include:
- Fixed story points
- Dedicated maintenance sprint
- Rotating remediation cycles
- Shared engineering capacity
Inside Scrum environments, those decisions usually happen during refinement and sprint planning ceremonies. That structure matters because allocation becomes part of normal governance. Engineers no longer need to defend this work as an informal side initiative.
Product stakeholders may still push for temporary reductions when deadlines tighten. Once this capacity disappears repeatedly, release predictability usually deteriorates over the following quarters.
Step 5. Implement Incremental Refactoring
Large rewrites concentrate risk, while smaller refactoring cycles distribute it across manageable iterations. For most engineering teams, incremental refactoring creates a more sustainable resolution path.
Early improvements appear modest. A duplicated service gets simplified. An outdated dependency is replaced, or a fragile workflow becomes easier to validate automatically during deployment.
Those smaller corrections begin compounding into broader structural gains. Release coordination becomes easier, debugging effort decreases, and teams regain confidence when modifying older parts of the codebase.
Under this approach, resolution work stays connected to ongoing product delivery. It becomes part of the normal development rhythm, without requiring a separate implementation timeline.
AnyforSoft’s work with Wittenborg University of Applied Sciences followed that same logic. When the university needed an AI assistant for applicants and students, it was introduced as a new Drupal module on the existing platform foundation. No rebuild was required. The assistant handles admissions and program queries grounded in official university content.
Step 6. Strengthen Engineering Practices (CI/CD, code review, testing)
As review workflows become more consistent, fewer unstable changes reach production environments. Strong engineering practices slow the accumulation of new issues while older ones are resolved incrementally.
Reliable engineering workflows usually include:
- CI/CD pipelines. Automated validation reduces deployment instability before changes reach production.
- Code review processes. Peer review catches fragile implementation patterns earlier in the release cycle.
- Automated testing. Regression risk becomes easier to control across larger applications and services.
- Branch protection rules. Teams maintain more consistent release standards across contributors and repositories.
Engineering teams centralize those workflows inside Github, where deployment pipelines, branch protections, and review requirements can be enforced automatically. That consistency reduces process drift across contributors.
Stronger engineering discipline improves engineering productivity directly. Less effort goes into reactive debugging, emergency fixes, and manual validation. More capacity remains available for planned development work.
Step 7. Track, Measure, and Prevent Recurrence
When oversight disappears, unresolved issues begin accumulating again in the background. Addressing technical debt reduces risk temporarily, but long-term stability depends on continuous monitoring and review.
Engineering teams establish recurring audit cadences, backlog reviews, dependency alerts, and ownership checkpoints after major efforts conclude. The goal is to detect new problem patterns before they spread across larger parts of the codebase.
A well-maintained register supports that process by keeping history, ownership, and unresolved risks accessible over time. Tooling matters here because undocumented issues often become invisible during normal sprint planning cycles.
Continuous review also protects long-term code scalability. As products grow, small structural weaknesses can expand into broader release constraints. Without ongoing monitoring, maintainability problems tend to spread across the codebase unnoticed.Teams planning how to scale a software product usually find that sustainable scaling depends on controlled technical evolution. Infrastructure expansion creates new capacity; a stable technical foundation determines whether that capacity holds.
Strategies to Reduce Technical Debt
Effective technical debt remediation rarely depends on one large cleanup initiative alone. Long-term improvement comes from strategies that fit naturally into existing Agile delivery workflows and continue working across release cycles.
The approaches below complement the step-by-step process described earlier. They strengthen the way teams build, review, test, and maintain software over time.
The Boy Scout Rule (leave the code cleaner than you found it)
Small improvements rarely look significant individually. Across dozens of commits and release cycles, those corrections push the codebase toward more stable clean code standards.
The principle is straightforward: every engineer leaves the surrounding implementation slightly better than it was before the change began. The discipline accumulates value across the delivery cycle.
Common examples include:
- Simplifying duplicated logic
- Renaming unclear methods
- Removing unused conditions
- Improving inline comments
These adjustments happen during regular commits. The codebase improves without forcing teams into disruptive rewrite projects.
Strangler Fig Pattern for Legacy Systems
Systems that cannot be rewritten in one phase benefit from phased replacement strategies. The Strangler Fig pattern works by introducing new functionality alongside the existing legacy system, keeping both running during the transition.
As engineers redirect traffic and workflows toward newer components, the legacy layer loses responsibility incrementally. Risk stays distributed across smaller transition stages. A large deployment concentrates that exposure in a way that this model avoids.
Older platforms with tightly coupled integrations, undocumented business rules, fragile data models, or hard-to-isolate dependencies make this approach especially valuable. Organizations pursuing legacy application modernization adopt similar phased strategies to avoid destabilizing critical systems during the transition.
Across release cycles, the legacy layer loses responsibility until it can be removed with minimal disruption.
Refactoring Sprints and Debt-Specific Backlogs
The most effective backlogs separate strategic work from routine feature requests. Without that distinction, urgent delivery tasks absorb nearly all available engineering attention.
Backlog separation determines whether strategic work survives delivery pressure. Some organizations schedule dedicated refactoring sprints twice per quarter. Others maintain a continuously updated tech debt backlog that flows into normal sprint planning alongside product items.
The format matters less than the discipline behind it. Items on the list should remain scoped, prioritized, owned, and connected to measurable outcomes. A queue that grows without clear ownership stops functioning as a reliable guide.
Clear ownership also matters. Once items stop reflecting active delivery risk, prioritization credibility erodes with both engineering leadership and product stakeholders.
Automated Testing as a Debt Prevention Layer
When test coverage becomes reliable, engineering teams gain a safer environment for code-level change. Automated testing reduces the likelihood that refactoring effort silently introduces regressions across unrelated parts of the application.
The protection runs in both directions. Existing functionality becomes easier to validate, and future output accumulates less hidden instability.
Strong validation pipelines also improve confidence during routine deployment cycles. Teams spend less effort on repetitive manual verification and more time improving code quality directly.
The test layer is what makes structural change predictable. Its coverage determines how much risk refactoring carries into production. Gaps surface first as unexpected regressions, then as confidence problems during deployment planning.
Dependency Management and Regular Upgrades
Dependencies left untouched accumulate as liabilities. Unsupported libraries and aging integrations increase both security exposure and version complexity as the gap widens.
Healthy workflows schedule upgrades as regular activity.
Compatibility reviews happen before deployment, which keeps framework and library changes from introducing integration failures downstream.
A sustainable workflow often includes:
- Automated scanning. Tools such as SNYK continuously monitor dependency vulnerabilities and outdated packages.
- Scheduled upgrade windows. Smaller updates applied consistently reduce the risk of disruptive consolidation projects later.
- Compatibility reviews. Teams verify how framework and library changes affect integrations before deployment.
- Version tracking. Engineering groups maintain awareness of unsupported or aging components across environments.
A predictable update cadence simplifies long-term coordination. Infrastructure stays easier to maintain and engineering teams avoid the compounding instability that appears inside neglected dependency chains.
AI and Automation in Technical Debt Reduction
AI systems are changing how engineering teams approach technical debt at scale. Activities that once depended on time-intensive review cycles can now run without interruption across codebases, deployment pipelines, infrastructure environments, and interconnected components.
AI-Assisted Code Review and Refactoring
Pull request reviews no longer depend entirely on human inspection.
Modern AI systems evaluate code structure, flag architectural risks, detect coupling issues, and suggest alternatives before code reaches production.
These tools also support AI-assisted refactoring during routine development. Duplicated logic may be flagged automatically. Oversized methods can also be reorganized into smaller components during review.
The practical advantage comes from consistency.
Automated review systems continue scanning thousands of changes without fatigue. That consistency holds even during periods of high output.
In engineering organizations at scale, these capabilities increasingly become part of normal CI workflows, moving beyond isolated experimental use.
AnyforSoft applied that principle during the development of FilterSync, an AI-driven property maintenance verification platform. The AI module evaluates tenant-submitted filter photos and returns a Pass or Fail result based on condition, authenticity, and timing.
Low-confidence submissions route automatically to a human reviewer rather than triggering unnecessary technician dispatches. That escalation layer kept verification accuracy high across a portfolio of properties without expanding manual oversight.
Automated Technical Debt Detection Tools
As applications expand across repositories and services, human review becomes harder to sustain reliably. Automated debt detection removes the need for repetitive manual trawls by scanning repositories in the background.
Detection platforms rely on static code analysis to identify deeper weaknesses, insecure dependencies, duplicated logic, and maintainability risks at scale.
Typical detection output includes:
- Dependency vulnerabilities. Outdated or unsupported libraries that increase security exposure.
- Duplicated logic patterns. Repeated code that complicates future maintenance work.
- Unsafe architectural dependencies. Tightly coupled components that increase deployment risk.
- Reliability warnings. Fragile workflows or unstable code paths that affect deployment predictability.
Enterprise-grade tools such as coverity extend that visibility further. Security analysis and maintainability evaluation remain centralized inside the same shared environment, with defect tracking connected to the same workflow.
Engineering teams gain ongoing monitoring that supports earlier intervention, before problems surface in production.
ML-Driven Prioritisation and Risk Scoring
Debt items vary significantly in how much risk they carry for system stability and long-term code health.
ML-driven prioritization systems help engineering teams separate cosmetic issues from foundational weaknesses that threaten either.
Traditional triage often depends heavily on individual judgment. Machine learning models introduce contextual evaluation by analyzing delivery history, component relationships, defect frequency, and code complexity together.
This capability builds on Intelligent static analysis, which extends beyond syntax checks to evaluate contextual risk. A risky component chain may receive higher priority once the model detects its relationship to customer-facing workflows or critical deployment paths.
As these scoring systems mature, remediation planning becomes less reactive. Engineering organizations can allocate effort against measurable risk exposure, reducing reliance on fragmented backlog discussions and intuition.
Technical Debt Metrics: How to Measure and Track Technical Debt
Effective technical debt management requires more than periodic cleanup initiatives. Engineering teams need measurable signals that reveal how code health, release stability, systemic risk, and implementation overhead evolve over time.
Without reliable signals, debt discussions become subjective. Consistent baselines help organizations identify whether engineering health is improving or deteriorating across release cycles.
Five indicators appear repeatedly across mature engineering environments:
- Debt ratio
- Code coverage
- Cyclomatic complexity
- MTTR
- Lead time for changes
Debt ratio helps teams estimate how much remediation effort exists relative to feature development work. A rising ratio usually signals that feature pressure is outpacing long-term code health.
Code coverage maps validation strength across the application. Low coverage rarely causes immediate failures, yet unstable release behavior often becomes more common once testing gaps accumulate around critical workflows.
Cyclomatic complexity focuses on decision density inside the codebase. Highly complex methods become harder to debug and modify. Engineers must reason through a growing number of execution paths before changes can be validated with confidence.
Recovery indicators matter as well. MTTR, or mean time to recovery, reflects how quickly engineering teams can restore stability after incidents or deployment failures. Lead time for changes measures how long implementation work takes to move from development into production environments.
Viewed together, these signals help organizations understand whether engineering workflows remain sustainable under growing system complexity. Individual numbers rarely tell the full story in isolation.
Engineering teams centralize these signals using platforms such as SonarQube or Code Climate. Scoring systems allow engineering and product stakeholders to evaluate code health trends across repositories and services from a shared view.
A well-maintained debt register strengthens that picture further. Teams usually track:
- Severity level. Higher-risk items receive earlier remediation priority.
- Ownership. Clear responsibility prevents unresolved issues from remaining invisible across release cycles.
- Estimated remediation effort. Planning becomes more predictable once engineering capacity is tied to realistic implementation scope.
- Business impact. Teams can connect structural weaknesses directly to release friction, release instability, or support overhead.
- Status history. Historical tracking helps organizations identify recurring patterns across the full issue lifecycle.
Across release cycles, those monitoring practices become part of normal engineering governance. Debt visibility moves from periodic reporting into continuous planning activity.
Technical Debt Metrics: How to Measure and Track Technical Debt
Effective technical debt management requires more than periodic cleanup initiatives. Development teams need measurable signals that reveal how code health, system stability, systemic risk, and implementation overhead evolve over time.
Without reliable signals, these discussions become subjective. Consistent baselines help organizations identify whether codebase health is improving or deteriorating across iterations.
Five indicators appear repeatedly across mature engineering environments:
- Debt ratio
- Code coverage
- Cyclomatic complexity
- MTTR
- Lead time for changes
Debt ratio helps teams estimate how much remediation effort exists relative to feature development work. A rising ratio usually signals that feature pressure is outpacing long-term code health.
Code coverage maps validation strength across the application. Low coverage rarely causes immediate failures, yet unstable deployment behavior often becomes more common once testing gaps accumulate around critical workflows.
Cyclomatic complexity focuses on decision density inside the codebase. Highly complex methods become harder to debug and modify. Engineers must reason through a growing number of execution paths before changes can be validated with confidence.
Recovery indicators matter as well. MTTR, or mean time to recovery, reflects how quickly teams can restore stability after incidents or deployment failures. Lead time for changes measures how long implementation work takes to move from development into production environments.
Viewed together, these signals help organizations understand whether team workflows remain sustainable under growing system complexity. Individual numbers rarely tell the full story in isolation.
Teams centralize these signals using platforms such as Sonarqube or Codeclimate. Scoring systems allow engineering and product stakeholders to evaluate code health trends across repositories and services from a shared view.
A well-maintained debt register strengthens that picture further. Teams usually track:
- Severity level. Higher-risk items receive earlier remediation priority.
- Ownership. Clear responsibility prevents unresolved issues from remaining invisible across planning cycles.
- Estimated remediation effort. Planning becomes more predictable once available capacity is tied to realistic implementation scope.
- Business impact. Teams can connect structural weaknesses directly to shipping friction, deployment instability, or support overhead.
- Status history. Historical tracking helps organizations identify recurring patterns across the full issue lifecycle.
Across sprints, those monitoring practices become part of normal delivery governance. That visibility moves from periodic reporting into continuous planning activity.
Technical Debt Best Practices for Engineering Teams
Strong engineering practices reduce the likelihood that technical debt quietly rebuilds after the effort concludes. Teams that have worked through how to reduce technical debt systematically usually discover that long-term stability depends on engineering culture. Tooling supports that foundation but does not replace it.
Define Clear Quality Gates
Stable release workflows rely on consistent expectations before code reaches production. Definition-of-done policies, validation requirements, and review standards help protect long-term code quality across growing applications.
Engineering teams include lightweight pull request checklists inside normal release workflows. Common checkpoints include:
- Test coverage updates
- Documentation changes
- Dependency review
- Automated linting
Those controls reduce inconsistency early. Engineers spend less time correcting preventable issues during later review stages.
Keep Architecture Decisions Visible
Architectural decisions become harder to evaluate once the original reasoning disappears. Short architecture decision records, often called ADRs, help teams preserve technical context around integrations, infrastructure choices, deployment dependencies, or service boundaries.
That context becomes especially valuable during platform growth. New contributors can understand why earlier tradeoffs were made. That prevents the same architectural questions from resurfacing later.
Across release cycles, that documentation layer also reduces fragmented implementation patterns. Engineering teams maintain stronger alignment around code stability goals.
Treat Debt Discussions as Part of Delivery Planning
This work becomes inconsistent when it exists outside normal engineering governance. Teams that separate technical discussions entirely from roadmap planning usually struggle to sustain progress over time.
Healthy production environments integrate debt review directly into refinement sessions, backlog grooming, sprint planning, and retrospective discussions. Systemic risk, maintenance burden, release friction, and code health remain visible alongside feature priorities. Technical discussions stay part of normal planning cycles.
That integration also improves communication between engineering leadership and product stakeholders. The effort becomes easier to justify once release impact stays measurable and transparent.
Use Visibility Systems Instead of Informal Tracking
Teams that want to understand how to avoid technical debt long-term usually invest in clear signals. Memory and tribal knowledge break down quickly once systems expand across repositories, services, deployment environments, and infrastructure layers.
A technical radar helps teams map recurring problem categories and monitor progress across release cycles. Radar-style tracking surfaces which accumulate dependency risk, architectural instability, testing gaps, or configuration drift before those patterns spread further.
Clear signals change planning significantly. Structural problems become easier to prioritize before they expand into larger system constraints.
Why Teams Choose AnyforSoft for Technical Debt Remediation
Engineering teams bring in AnyforSoft as an outsourced custom software development and IT consulting partner when accumulated issues have started affecting release predictability or platform stability. The engagement combines hands-on engineering with structured technical debt remediation, delivered as part of a broader software product development offering. Teams get a partner who understands both the codebase and the business constraints around addressing it.
AnyforSoft Technical Debt Remediation Model

Full-Cycle Software Audit and Assessment
Every engagement begins with a structured software audit. The team scans the codebase, reviews infrastructure, examines deployment configurations, and interviews engineering contributors. The output is a complete picture of accumulated issues and their distribution across the system.
Findings are organized by severity, blast radius, remediation effort, and business impact. That structure gives engineering and product leadership a shared reference point before resolution work begins.
The audit closes with a prioritized findings report and a remediation roadmap. Teams receive a document they can act on immediately, with clear next steps attached to each finding and ownership assigned before the project moves forward.
AI-First Engineering Approach
AnyforSoft embeds AI tooling at every stage of the project. Each engagement begins with a structured tech health check, an initial assessment that uses AI-assisted scoring to establish baselines across code quality, test coverage, architectural stability, and dependency health. Detection systems scan repositories in the background, surfacing structural weaknesses, outdated components, and implementation fragility across the full codebase.
AI analysis handles the diagnostic groundwork, freeing engineering capacity for resolving issues that carry the highest impact on release stability. Refactoring recommendations and prioritization scoring draw on the same analysis layer, keeping decisions grounded in measurable signals throughout the engagement.
Legacy Modernisation Experience
AnyforSoft has delivered software modernization engagements across education, fintech, media, and AI-enabled systems. Projects have included enterprise multilingual platforms, tightly coupled legacy codebases, content-heavy publishing systems, and infrastructure serving industries across fintech, education, and media. Imperial College Business School, Wittenborg University of Applied Sciences, and Verifone each represented a different combination of legacy constraints and delivery risk.
For complex migration work, the team applies LLM-assisted modernization, using large language models to analyze inherited codebases. Structural patterns surface faster than manual review allows, reducing the time needed to define a safe migration path.
Outcomes across these projects included reduced maintenance overhead, cleaner component boundaries, improved deployment predictability, and platforms better positioned for future development.
Transparent Debt Register and Prioritisation
The debt register is a client-facing deliverable, built to remain useful after the project concludes. AnyforSoft builds it as a living reference that engineering and product teams can use independently. Each entry carries severity, ownership, estimated resolution effort, and a documented approach.
The register stays active throughout the project, reflecting the current state of the codebase as items are resolved and new ones surface. That continuity keeps prioritization visible to engineering leadership and product stakeholders. Planning discussions can extend beyond the immediate remediation scope.
Flexible Engagement Models
AnyforSoft structures projects across fixed-scope work, time-and-materials arrangements, dedicated team placements, and staff augmentation. The right model depends on how clearly the scope is defined and how much ongoing engineering involvement the platform requires.
Fixed-scope work fits best when audit findings are clear and the remediation path is bounded. Time-and-materials suits situations where scope develops as deeper investigation reveals additional constraints. Both models work within AnyforSoft’s standard delivery and reporting structure.
Platforms with sustained complexity or active product development running alongside remediation suit a dedicated team model. Engineering leadership gains a consistent, embedded partner whose context builds over time. That continuity supports both planned remediation and decisions that arise during normal delivery cycles.
FAQs
What is technical debt and why does it matter?
Technical debt refers to the compounded cost of shortcuts, deferred decisions, structural weaknesses, and inconsistent implementation standards inside a codebase. It surfaces through slower shipping cycles, harder debugging, reduced confidence when modifying existing code, and growing coordination overhead. Left unaddressed, it reshapes how much capacity remains available for planned development. Organizations that actively work to reduce technical debt typically report shorter debugging cycles and more consistent sprint output, patterns documented in Google’s DORA research on software delivery performance.
What are the most common causes of technical debt?
The most common causes trace back to feature pressure, insufficient quality gates, inconsistent review standards, and contributor turnover. When sprint cycles run without adequate validation checkpoints, implementation shortcuts accumulate quickly. Teams often lack visibility into how widespread those patterns have become until a formal review begins. Each new contributor brings different conventions, pushing implementation standards further from the original architecture. Missing test coverage and sparse documentation compound the problem by making existing issues harder to detect.
How do you prioritise which technical debt to fix first?
Understanding how to manage technical debt starts with separating issues by the risk they carry for system stability and team capacity. Four criteria produce a reliable prioritization framework: business impact, blast radius (the number of system areas an issue affects), estimated remediation effort, and output risk. Items affecting wide portions of the delivery lifecycle should move into immediate scheduling first. Lower-impact issues can remain in the backlog while higher-risk work proceeds. A maintained debt register makes those distinctions visible across sprints.
How long does it typically take to reduce technical debt?
Timeline depends on scope, severity, codebase complexity, and available capacity. A focused audit and that effort on a codebase of 100,000 to 500,000 lines typically runs between four and twelve weeks. Platforms with deep architectural constraints or fragile infrastructure require longer cycles, often extending across two to four quarters. Teams that allocate a consistent percentage of each sprint to this work see measurable improvements in deployment predictability. That shift typically becomes visible within two to three months.
What is a technical debt register and how do you build one?
A technical debt register is a living record that tracks identified issues across severity, ownership, estimated remediation effort, and remediation status. Building one begins during the audit phase, where findings are catalogued against those dimensions before the work starts. Effective technical debt management depends on keeping the register active throughout the engagement. It should reflect current codebase conditions at every stage, not just at the point of handoff. Entries update as items are resolved, ownership shifts, or new issues surface during normal delivery cycles. Teams that maintain the register consistently find prioritization discussions easier to conduct and easier to communicate to product stakeholders.
How do you balance new feature development with debt remediation?
Most teams solve this by reserving between 10% and 20% of each sprint for this work. Managing technical debt alongside active product work requires treating that allocation as a protected commitment. When it disappears under deadline pressure, output predictability deteriorates across the following two to three quarters. The most effective teams keep that record inside refinement sessions and sprint planning. Debt review receives the same dedicated attention as feature work.
Which tools are best for measuring and tracking technical debt?
SonarQube and Code Climate provide continuous scoring across code quality, test coverage, architectural stability, and maintainability metrics. Both are used across enterprise and mid-market engineering teams for ongoing visibility across repositories and services. Ndepend extends that capability for .NET environments, offering dependency analysis, code metrics, architectural constraint tracking, and quality gate enforcement. Dependabot handles the dependency layer, surfacing outdated libraries and security vulnerabilities automatically. Static analysis, dependency monitoring, and a maintained debt register each cover different risk dimensions. Used together, they surface a more complete picture of codebase health. No single tool covers all three layers
Can technical debt be fully eliminated?
The realistic goal is to continuously reduce technical debt to a level where it no longer disrupts output predictability or sprint throughput. Reaching zero is an unrealistic target for codebases under active delivery. New shortcuts accumulate during normal cycles. The aim shifts toward knowing how to avoid technical debt building faster than it is resolved. Consistent quality gates and regular audit cadences keep accumulation rates below the threshold where debt starts reshaping output speed. That balance is what long-term platform stability depends on.
How can AI help identify and reduce technical debt?
AI systems contribute to debt reduction at four points in the process: detection, prioritization, refactoring guidance, and dependency oversight. Detection tools scan repositories in the background, surfacing structural weaknesses, dependency risks, implementation fragility, and outdated components faster than manual review allows. ML-driven prioritization systems analyze delivery history, component relationships, defect patterns, and code complexity to score each item by systemic risk. During refactoring, AI-assisted refactoring tools flag duplicated logic, oversized methods, unsafe implementation patterns, and fragile dependencies before changes reach production. These tools work better when connected to a maintained debt register and a consistent review workflow. That connection keeps prioritization decisions grounded in measurable signals.
What AI-powered tools are used for automated code refactoring?
Platforms such as GitHub Copilot and Amazon CodeWhisperer provide AI-assisted refactoring suggestions during active development. Both flag implementation issues as engineers write code. DeepSource and SonarQube both offer automated testing pattern detection with refactoring guidance for common structural weaknesses. For dependency-specific work, Dependabot surfaces outdated libraries and generates automated pull requests to keep components current. Static code analysis covers structural weaknesses and code quality patterns. Dependency monitoring surfaces outdated components and security exposure. A maintained debt register connects both layers to resolution planning.


